Description
On-line accumulation of rank-based statistics.
Description
A new data structure for accurate on-line accumulation of rank-based statistics such as quantiles and trimmed means.
See original paper: "Computing extremely accurate quantiles using t-digest" by Ted Dunning and Otmar Ertl for more details https://github.com/tdunning/t-digest/blob/07b8f2ca2be8d0a9f04df2feadad5ddc1bb73c88/docs/t-digest-paper/histo.pdf.
README.md
tdigest
A new data structure for accurate on-line accumulation of rank-based statistics such as quantiles and trimmed means.
See original paper: "Computing extremely accurate quantiles using t-digest" by Ted Dunning and Otmar Ertl
Synopsis
λ *Data.TDigest > median (tdigest [1..1000] :: TDigest 3)
Just 499.0090729817737
Benchmarks
Using 50M exponentially distributed numbers:
- average: 16s; incorrect approximation of median, mostly to measure prng speed
- sorting using
vector-algorithms: 33s; using 1000MB of memory - sparking t-digest (using some
par): 53s - buffered t-digest: 68s
- sequential t-digest: 65s
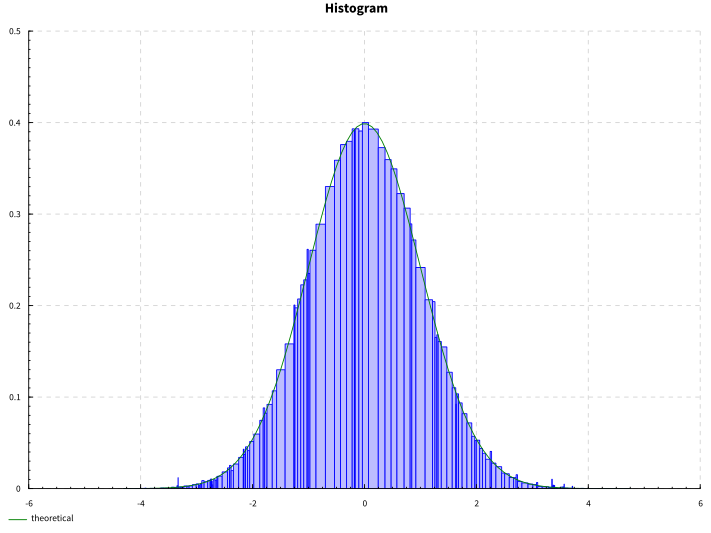
Example histogram
tdigest-simple -m tdigest -d standard -s 100000 -c 10 -o output.svg -i 34
cp output.svg example.svg
inkscape --export-png=example.png --export-dpi=80 --export-background-opacity=0 --without-gui example.svg