Using the Docker Container to Create R Workers on Local or Cloud Platform.
Note
The package DockerParallel is still under development, if you find any package which is not available on CRAN or not behaves as this vignette described, please consider to reinstall it from my GitHub repository.
Introduction
Parallel computing has became an important tool to analysis large and complex data. Using the parallel package to create local computing cluster is probably the simplest and most well-known method for the parallel computing in R's realm. As the advance of the cloud computing, there is a natural need to run R parallel cluster on the cloud to utilize the power of the cloud computing. DockerParallel is a package which is designed for the cloud computing. It aims to provide an easy-to-learn, highly scalable and low-cost tool to make the cloud computing possible.
The core component of DockerParallel, as its name implies, is the docker container. Container is a technique to package up code and all its dependencies in a standard unit and run it in an isolated environment from the host OS. By containerizing R's worker node, DockerParallel can easily deploy hundreds of identical workers in a cloud environment regardless of the host hardware and operating system. In this vignette, we will demonstrate how to use DockerParallel to run a cluster using Amazon Elastic Compute Service(ECS). The purpose of this vignette is providing the basic usage of the package for the user. For more information, please see the R markdown file developer-cookbook.
The structure of DockerParallel
For understanding the structure of DockerParallel, imagine that if someone tells you to create an R parallel cluster on the cloud using the container, what question you will ask before you can deploy the cluster on the cloud? Generally speaking, the cluster depends on the answers to these three questions:
- Which container should be used?
- Who provides the container service?
- What is the cluster configuration(e.g. worker number, CPU, memory)?
DockerParallel answers these questions via three components: DockerContainer, CloudProvider and CloudConfig. These components can be summarized in the following figure

DockerContainer determines the base environment and the parallel framework the worker uses. CloudProvider provides the functions to deploy a container on the cloud. CloudConfig stores the cluster information. We would not discuss the technical details of these components as they should be only interesting for the developer. Users only need to have a basic impression on what these components for. The workflow of the DockerParallel package is as follow
- Select a cloud provider(Available: ECSFargateProvider, AKSProvider)
- Select a container(Available: doRedisContainer, RedisParamContainer)
- Create the cluster and run your parallel task
In the rest of the vignette we will introduce them step by step.
The parallel framework using ECS as an example
Amazon provides Elastic Compute Service(ECS) to take over the management of the physical server. By using ECS, the user only needs to prepare the container image and ECS will find the best server to run the container. ECS provides both the traditional server and fargate as the host machine of the container. For the traditional server, the user is able to select a set of hardware that can run the container. For the fargate launch type, it does not refer to any particular server. The choice of the server is determined by Amazon and is opaque to the user. The user only need to specify the CPU and memory that a container needs. Therefore, it greatly simplifies the deployment of the container.
In this vignette, We use the foreach parallel framework and doRedis backend. We deploy the container using the ECS fargate launch type. Below is the diagram of how DockerParallel works with ECS and foreach doRedis container
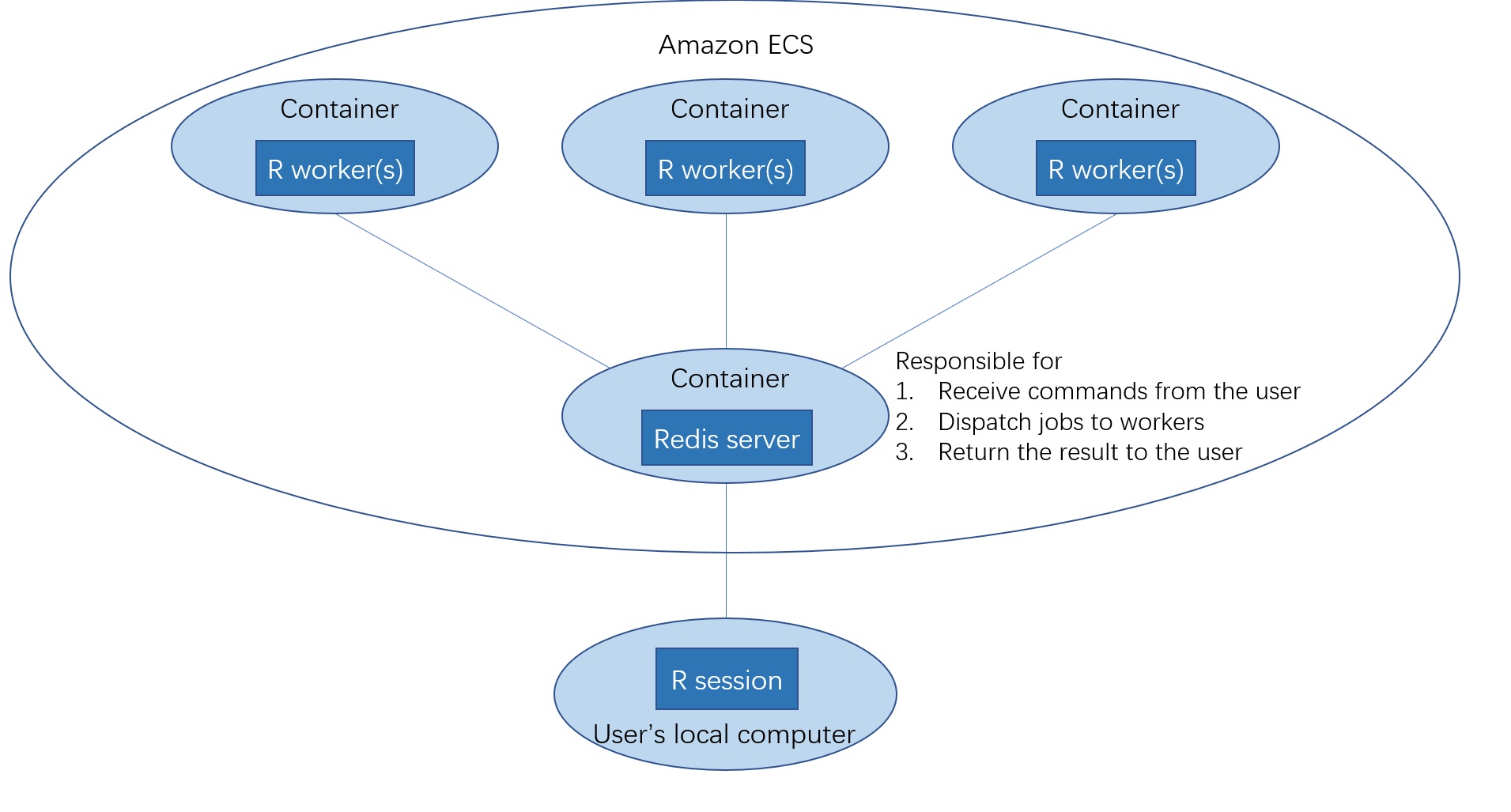
The cluster object is created in your local R session, but the workers and redis server are from Amazon ECS. Each docker container contains one or more R workers, they will receive jobs sent by your local R session and do the parallel computing.
Select a cloud provider
For selecting the ECS fargate provider, you need to create the provider object via ECSFargateProvider
## Load the ECS fargate provider package
library(ECSFargateProvider)
provider <- ECSFargateProvider()
provider
#> Region: us-east-1
#> Cluster name: docker-parallel-cluster
#> Server task definition: R-server-task-definition
#> Worker task definition: R-worker-task-definition
#> Security group name: R-parallel-security-group
#> VPC ID:
#> Subnet ID:
#> Security group ID:
#> Internet gateway ID:
#> Route table ID:
Please note that by the cloud provider is changeable and different providers provide different cloud service. As using the cloud service involves the authentication process, you need to have an Amazon account before using the ECS provider.
Credentials
For communicating with the cloud, you need to authenticate with the cloud provider. Amazon cloud uses access key id and secret access key to verify your identity. You can find the instruction on how to download your credentials from AWS Documentation. The ECS fargate provider uses aws_set_credentials from the package aws.ecx to find your credentials
aws.ecx::aws_set_credentials()
#> $access_key_id
#> [1] "AK**************OYX3"
#>
#> $secret_access_key
#> [1] "mL**********************************XGGH"
#>
#> $region
#> [1] "us-east-1"
aws_set_credentials determines your credentials as well as the region of the cloud service. The region is the physical location of the cloud servers that will run your worker nodes. The function uses a variety of ways to find such information. The most important methods are as follow(sorted by the search order):
user-supplied values passed to the function
environment variables
AWS_ACCESS_KEY_ID,AWS_SECRET_ACCESS_KEY,AWS_DEFAULT_REGION, andAWS_SESSION_TOKEN
You can either explicitly specify them or provide them as environment variables.
Select a container
Similar to the cloud provider, the container is also selectable and provides different running environment and parallel backend. Currently we provides r-base or Bioconductor container image with doRedis or RedisParam backend, the container can be made by
## Create the r-base foreach doRedis container image
library(doRedisContainer)
workerContainer <- doRedisWorkerContainer(image = "r-base")
workerContainer
#> Redis container reference object
#> Image: docker.io/dockerparallel/r-base-worker:latest
#> backend: doRedis
#> maxWorkers: 4
#> R packages:
#> system packages:
#> Environment variables:
This should be enough for creating the cluster. However, if you want to have more control over the container, the server container can be obtained from the worker container via
## Equivalent to: doRedisServerContainer()
serverContainer <- getServerContainer(workerContainer)
serverContainer
#> Redis container reference object
#> Image: docker.io/dockerparallel/redis-r-server:latest
#> backend:
#> maxWorkers: 1
#> R packages:
#> system packages:
#> Environment variables:
Create the cluster and run your parallel task
Once you have selected the provider and container, the cluster can be made by
cluster <- makeDockerCluster(
cloudProvider = provider,
workerContainer = workerContainer,
workerNumber = 1,
workerCpu = 1024,
workerMemory = 2048
)
cluster
#> Server status: Stopped
#> Worker Number: 1 / 0 / 0 (expected/running/initializing)
where workerCpu defines the CPU unit used by the worker container, 1024 CPU unit corresponds to a single CPU core. workerMemory defines the worker memory and the unit is MB. You do not have to provider the server container as it will be implicitly generated from the worker container.
For simplifying the cluster creation process, the package provides clusterPreset for quickly choosing the provider and container as the default values. In this case, you do not need to specify the provider and container arguments when calling makeDockerCluster.
## Set ECSFargateProvider and r-base doRedis container as the default
clusterPreset(cloudProvider = "ECSFargateProvider", container = "rbaseDoRedis")
cluster <- makeDockerCluster(
workerNumber = 1,
workerCpu = 1024,
workerMemory = 2048
)
cluster
#> Server status: Stopped
#> Worker Number: 1 / 0 / 0 (expected/running/initializing)
Until now, the cluster has not been started and nothing is running on the cloud, you need to start the cluster by
cluster$startCluster()
#> Checking if the cluster exist
#> Deploying server container
#> The cluster has 1 workers
#> Setting worker number to 1
#> Deploying worker container
#> Registering parallel backend, it might take a few minutes
Depending on the provider, the cluster creation process might be fast or slow. You can adjust the worker number after the cluster has been created
cluster$setWorkerNumber(2)
#> Setting worker number to 2
#> Deploying worker container
Once the cluster has been started, you can use the corresponding function provided by the parallel package to do the parallel computing as usual. In our case, we use the foreach package and the function is foreach
library(foreach)
foreach(i = 1:2)%dopar%{
Sys.info()
}
#> [[1]]
#> sysname release
#> "Linux" "4.14.225-168.357.amzn2.x86_64"
#> version nodename
#> "#1 SMP Mon Mar 15 18:00:02 UTC 2021" "cc1f05e863944abfb74b99f2cca2130c-1898378499"
#> machine login
#> "x86_64" "unknown"
#> user effective_user
#> "root" "root"
#>
#> [[2]]
#> sysname release
#> "Linux" "4.14.225-168.357.amzn2.x86_64"
#> version nodename
#> "#1 SMP Mon Mar 15 18:00:02 UTC 2021" "cc1f05e863944abfb74b99f2cca2130c-1898378499"
#> machine login
#> "x86_64" "unknown"
#> user effective_user
#> "root" "root"
After finishing the computation, you can stop the cluster via
cluster$stopCluster()
#> Stopping cluster
#> Setting worker number to 0
By default, the cluster will stop itself if it has been removed from the R session, but we recommended to explicitly stop it after use for avoiding the unexpected network issue.
The cluster methods and parameters
Here is a list of methods and parameters defined in the cluster and the short explanation.
startCluster: Start the cluster. It first start the server, then start the worker and register the parallel backend.stopCluster: Stop the cluster.startServer: Start the server only.stopServer: Stop the server only.isServerRunning: Whether the server is running or not.setWorkerNumber: Set the expected worker number, if the server is not running, the worker will not be deployed.getWorkerNumbers: Get the expected, running, initializing worker number. The worker is only reachable when it is in the running status.registerBackend: Register the parallel backend.deregisterBackend: Deregister the parallel backend. In most case, it will replace the parallle backend with the serialize backend.update: Update the server status and the worker number. If the server is running and the worker number does not match the expected number, the cluster will try to deploy more workers.clusterExists: Whether the cluster with the same job queue name has existed on the cloud.reconnect: Reconnect to the cluster if it has existed on the cloud.verbose: The verbose level.stopClusterOnExit: Whether to stop the cluster when it has been removed from the R session.
Advanced topic
In this document, we will introduce some advanced topics related to the package. Please note that the some features described in this section may not be available for all cloud providers and container, they should be treated as the additional features.
Installing the system packages
Some R packages require the system dependence before they can be installed. The system packages can be added via addSysPackages in the container object. For example
cluster$workerContainer$addSysPackages(c("package1", "package2"))
#> [1] "package1" "package2"
cluster$workerContainer$getSysPackages()
#> [1] "package1" "package2"
When the contain is deployed, the system packages will be installed via apt-get install before the start of the R workers. Note that this function only work with the incoming worker container. It has no effect on the current running container. The server container does not support this operation. You can also set the system packages using
cluster$workerContainer$setSysPackages(c("package1", "package2"))
#> [1] "package1" "package2"
The difference between addSysPackages and setSysPackages is that the latter one will overwrite the existing package setting.
Installing the R packages
Users can ask the worker to install some R packages before connecting with the server via addRPackages in the container object. The workers will install the packages through AnVIL::install, which provides the fast binary installation. If the binary is not available, it will call BiocManager::install to install the package. The GitHub package will be installed by remotes::install_github. For example, the package S4Vectors can be installed via
cluster$workerContainer$addRPackages("S4Vectors")
#> [1] "S4Vectors"
cluster$workerContainer$getRPackages()
#> [1] "S4Vectors"
Similar to addSysPackages, this feature does not work with the existing container. The server container does not support this operation. You can also call setRPackages to set the required packages.
SSH to the container
Sometimes it might be helpful to ssh into the container and look at the debug information. The package can search for your public key file through the environment variable DockerParallelSSHPublicKey. If the public key file is available, it can be used by the container object and allow you to access the container using your private key. If you want to explicitly provide a public key, this can be done via
setSSHPubKeyPath(publicKey = "Path-to-your-key")
If you want to see the current key file
getSSHPubKeyPath()
The ssh key value can be found by
getSSHPubKeyValue()
Note that the availability of the SSH service depends on the implementation of both the cloud provider and container. The formal one needs to allow the ssh access to the container and the latter one needs to run the SSH server inside the container. The ECS fargate provider and the container package doRedisContainer and RedisParamContainer support the SSH access. Users can find the worker's log file from /workspace/log
Session info
sessionInfo()
#> R version 4.1.0 RC (2021-05-10 r80296)
#> Platform: x86_64-w64-mingw32/x64 (64-bit)
#> Running under: Windows 10 x64 (build 19042)
#>
#> Matrix products: default
#>
#> locale:
#> [1] LC_COLLATE=English_United States.1252 LC_CTYPE=English_United States.1252
#> [3] LC_MONETARY=English_United States.1252 LC_NUMERIC=C
#> [5] LC_TIME=English_United States.1252
#> system code page: 936
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] foreach_1.5.1 DockerParallel_1.0.3 doRedisContainer_0.99.0
#> [4] ECSFargateProvider_1.0.2
#>
#> loaded via a namespace (and not attached):
#> [1] magrittr_2.0.1 cluster_2.1.2 knitr_1.33
#> [4] xml2_1.3.2 aws.signature_0.6.0 rjson_0.2.20
#> [7] R6_2.5.0 aws.ecx_1.0.4 stringr_1.4.0
#> [10] httr_1.4.2 tools_4.1.0 parallel_4.1.0
#> [13] lpSolve_5.6.15 xfun_0.23 RedisBaseContainer_1.0.0
#> [16] doRedis_2.0.1 iterators_1.0.13 digest_0.6.27
#> [19] aws.iam_0.1.8 adagio_0.8.4 base64enc_0.1-3
#> [22] codetools_0.2-18 curl_4.3.1 evaluate_0.14
#> [25] redux_1.1.0 stringi_1.6.2 compiler_4.1.0
#> [28] ManagedCloudProvider_1.0.0 jsonlite_1.7.2