Risk Measures for (Financial) Networks.


The Network Risk Measures (NetworkRiskMeasures) package implements a set of tools to analyze systemic risk in (financial) networks in a unified framework. We currently have implemented:
- matrix reconstruction methods such as the maximum entropy (Upper, 2004) and minimum density estimation (Anand et al, 2015);
- a flexible contagion algorithm with: (i) threshold propagation (traditional default cascades), (ii) linear propagation (aka DebtRank – Battiston et al (2012) and Bardoscia et al (2105)), (iii) a combination of threshold and linear propagation (iv) as well as any other custom propagation function provided by the user.
- network risk measures based on the communicability matrix such as: impact susceptibility, impact diffusion and impact fluidity (Silva et al 2015a and 2015b).
CRAN
To install the CRAN version run:
install.packages("NetworkRiskMeasures")
How to install the development version from GitHub
To install the GitHub version you need to have the package devtools installed. Make sure to set the option build_vignettes = TRUE to compile the package vignette (not available yet).
# install.packages("devtools") # run this to install the devtools package
devtools::install_github("carloscinelli/NetworkRiskMeasures", build_vignettes = TRUE)
We are looking for interesting public datasets!
Most bilateral exposures data are confidential and can’t be used as examples on the package. So we are looking for interesting, public datasets on bilateral exposures for that purpose. If you have any suggestions, please let us know!
Example usage
Filling in the blanks: estimating the adjacency matrix
Many regulators have data on total interbank exposures but do not observe the network of bilateral exposures. That is, they only know the marginals of the interbank adjacency matrix. Consider the example below with 7 fictitious banks – banks A through G (Anand et al, 2015, p.628):
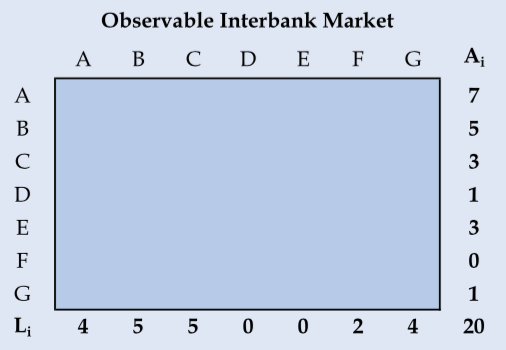
We know how much each bank has in the interbank market in the form of assets and liabilities (row and column sums)–but we do not know how each bank is related to each other. In those cases, if one wants to run contagion simulations or assess other risk measures, it is necessary to estimate the interbank network.
Two popular methods for this task are the maximum entropy (Upper, 2004) and minimum density estimation (Anand et al, 2015). These two methods are already implemented on the package. So, let’s build the interbank assets and liabilities vectors of our example (which are the row and column sums of the interbank network) to see how the estimation function works:
# Example from Anand, Craig and Von Peter (2015, p.628)
# Total Liabilities
L <- c(a = 4, b = 5, c = 5, d = 0, e = 0, f = 2, g = 4)
# Total Assets
A <- c(a = 7, b = 5, c = 3, d = 1, e = 3, f = 0, g = 1)
For the maximum entropy estimation we can use the matrix_estimation() function by providing the row (assets) sums, column (liabilities) sums and the parameter method = "me". The maximum entropy estimate of the interbank network assumes that each bank tries to diversify its exposures as evenly as possible, given the restrictions.
# Loads the package
library(NetworkRiskMeasures)
#> Loading required package: Matrix
# Maximum Entropy Estimation
ME <- matrix_estimation(rowsums = A, colsums = L, method = "me")
#> Starting Maximum Entropy estimation.
#>
#> - Iteration number: 1 -- abs error: 2.0356
#> - Iteration number: 2 -- abs error: 0.0555
#> - Iteration number: 3 -- abs error: 0.004
#> - Iteration number: 4 -- abs error: 3e-04
#>
#> Maximum Entropy estimation finished.
#> * Total Number of Iterations: 4
#> * Absolute Error: 3e-04
The resulting adjacency matrix is:
ME <- round(ME, 2)
ME
#> a b c d e f g
#> a 0.00 2.53 2.18 0 0 0.74 1.55
#> b 1.72 0.00 1.60 0 0 0.54 1.14
#> c 0.98 1.06 0.00 0 0 0.31 0.65
#> d 0.25 0.27 0.23 0 0 0.08 0.17
#> e 0.75 0.81 0.70 0 0 0.24 0.50
#> f 0.00 0.00 0.00 0 0 0.00 0.00
#> g 0.30 0.32 0.28 0 0 0.09 0.00
This solution may work well in some cases, but it does not mimic some properties of interbank networks, which are known to be sparse and disassortative. Therefore, one proposed alternative to the maximum entropy is the “minimum density” estimation by Anand et al (2015). To do that in R, just change the parameter method to "md" in the matrix_estimation() function:
# Minimum Density Estimation
set.seed(192) # seed for reproducibility
MD <- matrix_estimation(A, L, method = "md")
#> Starting Minimum Density estimation.
#>
#> - Iteration number: 1 -- total alocated: 0 %
#> - Iteration number: 2 -- total alocated: 20 %
#> - Iteration number: 3 -- total alocated: 25 %
#> - Iteration number: 4 -- total alocated: 30 %
#> - Iteration number: 5 -- total alocated: 30 %
#> - Iteration number: 6 -- total alocated: 30 %
#> - Iteration number: 7 -- total alocated: 30 %
#> - Iteration number: 8 -- total alocated: 30 %
#> - Iteration number: 9 -- total alocated: 30 %
#> - Iteration number: 10 -- total alocated: 30 %
#> - Iteration number: 11 -- total alocated: 45 %
#> - Iteration number: 12 -- total alocated: 45 %
#> - Iteration number: 13 -- total alocated: 55 %
#> - Iteration number: 14 -- total alocated: 60 %
#> - Iteration number: 15 -- total alocated: 60 %
#> - Iteration number: 16 -- total alocated: 60 %
#> - Iteration number: 17 -- total alocated: 75 %
#> - Iteration number: 18 -- total alocated: 90 %
#> - Iteration number: 19 -- total alocated: 90 %
#> - Iteration number: 20 -- total alocated: 90 %
#> - Iteration number: 21 -- total alocated: 90 %
#> - Iteration number: 22 -- total alocated: 100 %
#>
#> Minimum Density estimation finished.
#> * Total Number of Iterations: 22
#> * Total Alocated: 100 %
The resulting adjacency matrix is:
MD
#> a b c d e f g
#> a 0 3 0 0 0 0 4
#> b 3 0 2 0 0 0 0
#> c 0 2 0 0 0 1 0
#> d 0 0 0 0 0 1 0
#> e 0 0 3 0 0 0 0
#> f 0 0 0 0 0 0 0
#> g 1 0 0 0 0 0 0
We intend to implement other estimation methods used in the literature. For an overview of current proposed methods and how well they fit known networks, you may watch Anand’s presentation below:
The missing links: a global study on uncovering financial network structure from partial data from Cambridge Judge Business School on Vimeo.
Measuring risk: finding systemically important institutions and simulating scenarios
Two important questions:
- How can we find important or systemic institutions?
- How can we estimate the impact of shock scenarios, considering possible contagion effects?
The example data: simulated interbank network
For illustration purposes, the NetworkRiskMeasures package comes with a simulated dataset of interbank assets, liabilities, capital buffer and weights for 125 nodes. Let’s use it for our analysis:
# See the code to generate the dataset in the help files: ?sim_data.
data("sim_data")
head(sim_data)
#> bank assets liabilities buffer weights
#> 1 b1 0.37490927 9.6317127 5.628295 17.119551
#> 2 b2 0.66805904 0.7126552 2.847072 6.004475
#> 3 b3 0.79064804 0.3089983 3.983451 6.777531
#> 4 b4 0.02420156 0.6562193 5.657779 7.787618
#> 5 b5 0.65294261 0.9153901 4.446595 8.673730
#> 6 b6 0.60766835 0.3007373 2.252369 4.708805
In this example, we do not observe the real network, only the marginals (total assets and liabilities). Thus, we must estimate the adjacency matrix before running the contagion simulations or calculating other network measures. For now, we will use the minimum density estimation:
# seed - min. dens. estimation is stochastic
set.seed(15)
# minimum density estimation
# verbose = F to prevent printing
md_mat <- matrix_estimation(sim_data$assets, sim_data$liabilities, method = "md", verbose = F)
# rownames and colnames for the matrix
rownames(md_mat) <- colnames(md_mat) <- sim_data$bank
Once we have our network, we can visualize it either using igraph or ggplot2 along with the ggnetwork package. Below we give an example with ggplot2 – it’s useful to remember that we have an assets matrix, so a → b means that node a has an asset with node b:
library(ggplot2)
library(ggnetwork)
library(igraph)
# converting our network to an igraph object
gmd <- graph_from_adjacency_matrix(md_mat, weighted = T)
# adding other node attributes to the network
V(gmd)$buffer <- sim_data$buffer
V(gmd)$weights <- sim_data$weights/sum(sim_data$weights)
V(gmd)$assets <- sim_data$assets
V(gmd)$liabilities <- sim_data$liabilities
# ploting with ggplot and ggnetwork
set.seed(20)
netdf <- ggnetwork(gmd)
ggplot(netdf, aes(x = x, y = y, xend = xend, yend = yend)) +
geom_edges(arrow = arrow(length = unit(6, "pt"), type = "closed"),
color = "grey50", curvature = 0.1, alpha = 0.5) +
geom_nodes(aes(size = weights)) +
ggtitle("Estimated interbank network") +
theme_blank()
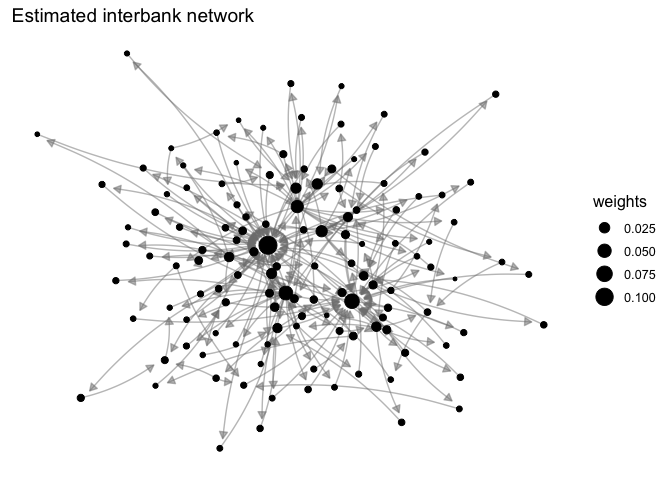
As one can see, the resulting network is sparse and disassortative:
# network density
edge_density(gmd)
#> [1] 0.01606452
# assortativity
assortativity_degree(gmd)
#> [1] -0.3676471
Finding central, important or systemic nodes on the network
How can we find the important (central) or systemic banks in our network?
Traditional centrality measures, impact susceptibility and impact diffusion
A first approach to this problem would be to use traditional centrality measures from network theory. You can calculate those easily with packages like igraph:
sim_data$degree <- igraph::degree(gmd)
sim_data$btw <- igraph::betweenness(gmd)
sim_data$close <- igraph::closeness(gmd)
sim_data$eigen <- igraph::eigen_centrality(gmd)$vector
sim_data$alpha <- igraph::alpha_centrality(gmd, alpha = 0.5)
Other interesting measures are the impact susceptibility and impact diffusion. These are implemented in the NetworkRiskMeasures package with the impact_susceptibility() and impact_diffusion() functions.
The impact susceptibility measures the feasible contagion paths that can reach a vertex in relation to its direct contagion paths. When the impact susceptibility is greater than 1, that means the vertex is vulnerable to other vertices beyond its direct neighbors (remotely vulnerable).
The impact diffusion tries to capture the influence exercised by a node on the propagation of impacts in the network. The impact diffusion of a vertex is measured by the change it causes on the impact susceptibility of other vertices when its power to propagate contagion is removed from the network.
sim_data$imps <- impact_susceptibility(exposures = gmd, buffer = sim_data$buffer)
sim_data$impd <- impact_diffusion(exposures = gmd, buffer = sim_data$buffer, weights = sim_data$weights)$total
Notice that both the traditional metrics and the communicability measures depend on network topology but do not depend on a specific shock.
Contagion metrics: default cascades and DebtRank
The previous metrics might not have an economically meaningful interpretation. So another way to measure the systemic importance of a bank is to answer the following question: how would the default of the entity impact the system?
To simulate a contagion process in the network we can use the contagion() function. The main arguments of the function are the exposure matrix, the capital buffer and the node’s weights. You may choose different propagation methods or even provide your own. Right now, let’s see only two different approaches for the propagation: the traditional default cascade and the DebtRank.
The DebtRank methodology proposed by Bardoscia et al (2015) considers a linear shock propagation — briefly, that means that when a bank loses, say, 10% of its capital buffer, it propagates losses of 10% of its debts to its creditors. If you run the contagion() function with parameters shock = "all" and method = "debtrank", you will simulate the default of each bank in the network using the DebtRank methodology (linear propagation).
# DebtRank simulation
contdr <- contagion(exposures = md_mat, buffer = sim_data$buffer, weights = sim_data$weights,
shock = "all", method = "debtrank", verbose = F)
summary(contdr)
#> Contagion Simulations Summary
#>
#> Info:
#> Propagation Function: debtrank
#> With parameters:
#> data frame with 0 columns and 0 rows
#>
#> Simulation summary (showing 10 of 125 -- decreasing order of additional stress):
#> Scenario Original Stress Additional Stress Original Losses Additional Losses Additional Defaults
#> b55 0.1102 0.29 58.44 235 18
#> b28 0.0638 0.20 63.45 117 9
#> b74 0.0161 0.15 14.37 48 5
#> b84 0.0236 0.13 7.61 72 4
#> b33 0.0243 0.12 27.44 46 4
#> b5 0.0038 0.12 4.45 27 4
#> b101 0.0070 0.11 9.31 25 3
#> b60 0.0057 0.11 0.67 26 3
#> b23 0.0032 0.11 5.39 22 2
#> b114 0.0055 0.10 5.23 31 3
What do these results mean?
Take, for instance, the results for bank b55. It represents 11% of our simulated financial system. However, if we consider a linear shock propagation, its default causes an additional stress of 28% of the system, with additional losses of $235.8 billion and the default of 18 other institutions. Or take the results for b69 — although it represents only 1.3% of the system, its default causes an additional stress of almost ten times its size.
plot(contdr)
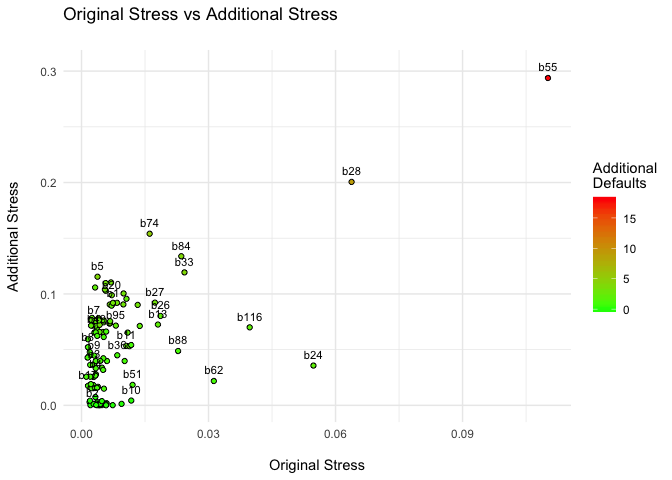
You don’t need to interpret these results too literally. You could use the additional stress indicator (the DebtRank) as a measure of the systemic importance of the institution:
contdr_summary <- summary(contdr)
sim_data$DebtRank <- contdr_summary$summary_table$additional_stress
One can also consider a different propagation method. For example, a bank may not transmit contagion unless it defaults. To do that, just change the contagion method to threshold.
# Traditional default cascades simulation
contthr <- contagion(exposures = md_mat, buffer = sim_data$buffer, weights = sim_data$weights,
shock = "all", method = "threshold", verbose = F)
summary(contthr)
#> Contagion Simulations Summary
#>
#> Info:
#> Propagation Function: threshold
#> With parameters:
#> data frame with 0 columns and 0 rows
#>
#> Simulation summary (showing 10 of 125 -- decreasing order of additional stress):
#> Scenario Original Stress Additional Stress Original Losses Additional Losses Additional Defaults
#> b55 0.1102 0.271 58.44 221.6 17
#> b28 0.0638 0.171 63.45 110.8 9
#> b27 0.0173 0.084 20.52 40.3 3
#> b69 0.0133 0.082 12.96 39.2 3
#> b74 0.0161 0.082 14.37 27.6 3
#> b33 0.0243 0.052 27.44 27.1 2
#> b84 0.0236 0.051 7.61 44.8 2
#> b5 0.0038 0.047 4.45 7.0 2
#> b101 0.0070 0.042 9.31 5.3 1
#> b60 0.0057 0.042 0.67 6.1 1
Let’s save the results in our sim_data along with the other metrics:
contthr_summary <- summary(contthr)
sim_data$cascade <- contthr_summary$summary_table$additional_stress
Now we have all of our indicators in the sim_datadata.frame:
head(sim_data)
#> bank assets liabilities buffer weights degree btw close eigen alpha imps impd DebtRank
#> 1 b1 0.37490927 9.6317127 5.628295 17.119551 3 2 0.6664736 0.0319455864 6.931642 0 41.39988 0.091307438
#> 2 b2 0.66805904 0.7126552 2.847072 6.004475 2 16 0.1146101 0.0027179985 1.935979 0 0.00000 0.001402345
#> 3 b3 0.79064804 0.3089983 3.983451 6.777531 2 0 0.1554913 0.0053344470 1.136058 0 0.00000 0.037028664
#> 4 b4 0.02420156 0.6562193 5.657779 7.787618 2 3 0.2048776 0.0002681628 1.488546 0 0.00000 0.027873667
#> 5 b5 0.65294261 0.9153901 4.446595 8.673730 2 1 0.5633181 0.0045861443 2.623180 0 58.60687 0.115430423
#> 6 b6 0.60766835 0.3007373 2.252369 4.708805 2 0 0.1812800 0.0047153984 1.132420 0 0.00000 0.036324739
#> cascade
#> 1 0.020415431
#> 2 0.001066810
#> 3 0.005638458
#> 4 0.001197128
#> 5 0.047389235
#> 6 0.005487714
We may see how some of these different metrics rank each of the nodes. For instance, the DebtRank and the Default Cascade indicators agree up to the first five institutions.
rankings <- sim_data[1]
rankings <- cbind(rankings, lapply(sim_data[c("DebtRank","cascade","degree","eigen","impd","assets", "liabilities", "buffer")],
function(x) as.numeric(factor(-1*x))))
rankings <- rankings[order(rankings$DebtRank), ]
head(rankings, 10)
#> bank DebtRank cascade degree eigen impd assets liabilities buffer
#> 55 b55 1 1 1 1 1 40 1 2
#> 28 b28 2 2 3 9 2 85 2 1
#> 74 b74 3 5 10 17 6 86 5 5
#> 84 b84 4 7 6 5 8 78 3 29
#> 33 b33 5 6 12 14 7 51 4 3
#> 5 b5 6 8 14 88 11 54 35 75
#> 101 b101 7 9 12 30 9 113 25 13
#> 60 b60 8 10 12 28 3 29 21 118
#> 23 b23 9 79 14 122 19 65 102 56
#> 114 b114 10 17 11 97 13 56 23 61
And the cross-correlations between the metrics:
cor(rankings[-1])
#> DebtRank cascade degree eigen impd assets liabilities buffer
#> DebtRank 1.00000000 0.80426225 0.3169750 0.3040417 0.5007757 -0.051199891 0.712515761 0.2921446
#> cascade 0.80426225 1.00000000 0.3851859 0.3576352 0.5924437 0.011386033 0.842053993 0.3342507
#> degree 0.31697496 0.38518588 1.0000000 0.5634597 0.5252610 0.360497221 0.433801190 0.2229232
#> eigen 0.30404170 0.35763517 0.5634597 1.0000000 0.3659061 0.544387097 0.437339478 0.1421813
#> impd 0.50077565 0.59244373 0.5252610 0.3659061 1.0000000 0.011901595 0.561766174 0.3953612
#> assets -0.05119989 0.01138603 0.3604972 0.5443871 0.0119016 1.000000000 0.004958525 -0.1198280
#> liabilities 0.71251576 0.84205399 0.4338012 0.4373395 0.5617662 0.004958525 1.000000000 0.3930261
#> buffer 0.29214458 0.33425068 0.2229232 0.1421813 0.3953612 -0.119827957 0.393026114 1.0000000
Simulating arbitrary contagion scenarios
The contagion() function is flexible and you can simulate arbitrary scenarios with it. For example, how would simultaneous stress shocks of 1% up to 25% in all banks affect the system? To do that, just create a list with the shock vectors and pass it to contagion().
s <- seq(0.01, 0.25, by = 0.01)
shocks <- lapply(s, function(x) rep(x, nrow(md_mat)))
names(shocks) <- paste(s*100, "pct shock")
cont <- contagion(exposures = gmd, buffer = sim_data$buffer, shock = shocks, weights = sim_data$weights, method = "debtrank", verbose = F)
summary(cont)
#> Contagion Simulations Summary
#>
#> Info:
#> Propagation Function: debtrank
#> With parameters:
#> data frame with 0 columns and 0 rows
#>
#> Simulation summary (showing 10 of 25 -- decreasing order of additional stress):
#> Scenario Original Stress Additional Stress Original Losses Additional Losses Additional Defaults
#> 22 pct shock 0.22 0.25 174 173 13
#> 23 pct shock 0.23 0.25 182 179 14
#> 21 pct shock 0.21 0.25 166 167 12
#> 24 pct shock 0.24 0.25 190 185 14
#> 25 pct shock 0.25 0.25 198 191 15
#> 20 pct shock 0.20 0.25 158 161 12
#> 19 pct shock 0.19 0.25 150 155 11
#> 18 pct shock 0.18 0.25 142 149 11
#> 17 pct shock 0.17 0.25 134 143 11
#> 16 pct shock 0.16 0.25 127 137 11
plot(cont, size = 2.2)
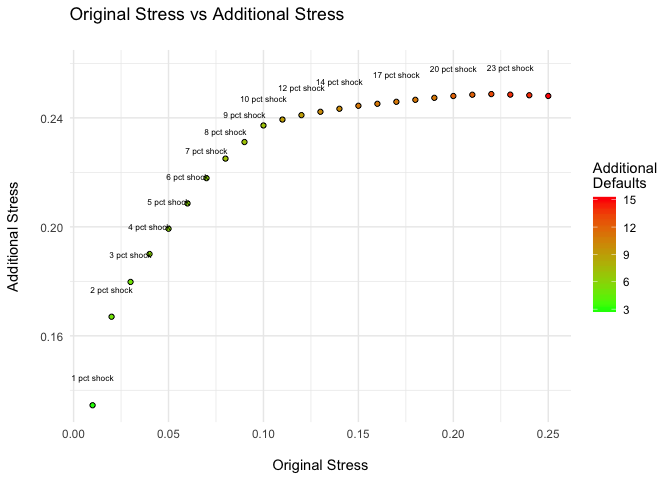
In this example, a 5% shock in all banks causes an additional stress of 20% in the system, an amplification of 4 times the initial shock.
Creating your own propagation method
To be expanded.