High Precision Timing of R Expressions.
bench
![]()
![]()
The goal of bench is to benchmark code, tracking execution time, memory allocations and garbage collections.
Installation
You can install the release version from CRAN with:
install.packages("bench")
Or you can install the development version from GitHub with:
# install.packages("pak")
pak::pak("r-lib/bench")
Features
bench::mark() is used to benchmark one or a series of expressions, we feel it has a number of advantages over alternatives.
- Always uses the highest precision APIs available for each operating system (often nanoseconds).
- Tracks memory allocations for each expression.
- Tracks the number and type of R garbage collections per expression iteration.
- Verifies equality of expression results by default, to avoid accidentally benchmarking inequivalent code.
- Has
bench::press(), which allows you to easily perform and combine benchmarks across a large grid of values. - Uses adaptive stopping by default, running each expression for a set amount of time rather than for a specific number of iterations.
- Expressions are run in batches and summary statistics are calculated after filtering out iterations with garbage collections. This allows you to isolate the performance and effects of garbage collection on running time (for more details see Neal 2014).
The times and memory usage are returned as custom objects which have human readable formatting for display (e.g. 104ns) and comparisons (e.g. x$mem_alloc > "10MB").
There is also full support for plotting with ggplot2 including custom scales and formatting.
Usage
bench::mark()
Benchmarks can be run with bench::mark(), which takes one or more expressions to benchmark against each other.
library(bench)
set.seed(42)
dat <- data.frame(
x = runif(10000, 1, 1000),
y = runif(10000, 1, 1000)
)
bench::mark() will throw an error if the results are not equivalent, so you don’t accidentally benchmark inequivalent code.
bench::mark(
dat[dat$x > 500, ],
dat[which(dat$x > 499), ],
subset(dat, x > 500)
)
#> Error: Each result must equal the first result:
#> `dat[dat$x > 500, ]` does not equal `dat[which(dat$x > 499), ]`
Results are easy to interpret, with human readable units.
bnch <- bench::mark(
dat[dat$x > 500, ],
dat[which(dat$x > 500), ],
subset(dat, x > 500)
)
bnch
#> # A tibble: 3 × 6
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#> 1 dat[dat$x > 500, ] 277µs 383µs 2485. 377KB 16.3
#> 2 dat[which(dat$x > 500), ] 203µs 276µs 3635. 260KB 16.9
#> 3 subset(dat, x > 500) 361µs 487µs 1981. 510KB 16.8
By default the summary uses absolute measures, however relative results can be obtained by using relative = TRUE in your call to bench::mark() or calling summary(relative = TRUE) on the results.
summary(bnch, relative = TRUE)
#> # A tibble: 3 × 6
#> expression min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 dat[dat$x > 500, ] 1.36 1.39 1.25 1.45 1
#> 2 dat[which(dat$x > 500), ] 1 1 1.84 1 1.03
#> 3 subset(dat, x > 500) 1.78 1.77 1 1.96 1.03
bench::press()
bench::press() is used to run benchmarks against a grid of parameters. Provide setup and benchmarking code as a single unnamed argument then define sets of values as named arguments. The full combination of values will be expanded and the benchmarks are then pressed together in the result. This allows you to benchmark a set of expressions across a wide variety of input sizes, perform replications and other useful tasks.
set.seed(42)
create_df <- function(rows, cols) {
out <- replicate(cols, runif(rows, 1, 100), simplify = FALSE)
out <- setNames(out, rep_len(c("x", letters), cols))
as.data.frame(out)
}
results <- bench::press(
rows = c(1000, 10000),
cols = c(2, 10),
{
dat <- create_df(rows, cols)
bench::mark(
min_iterations = 100,
bracket = dat[dat$x > 500, ],
which = dat[which(dat$x > 500), ],
subset = subset(dat, x > 500)
)
}
)
#> Running with:
#> rows cols
#> 1 1000 2
#> 2 10000 2
#> 3 1000 10
#> 4 10000 10
results
#> # A tibble: 12 × 8
#> expression rows cols min median `itr/sec` mem_alloc `gc/sec`
#> <bch:expr> <dbl> <dbl> <bch:tm> <bch:tm> <dbl> <bch:byt> <dbl>
#> 1 bracket 1000 2 27µs 34µs 27964. 15.84KB 19.6
#> 2 which 1000 2 25.7µs 33.4µs 29553. 7.91KB 17.7
#> 3 subset 1000 2 45.9µs 58.2µs 16793. 27.7KB 17.1
#> 4 bracket 10000 2 64.1µs 70.8µs 13447. 156.46KB 40.5
#> 5 which 10000 2 46.7µs 54.7µs 17586. 78.23KB 23.3
#> 6 subset 10000 2 116.2µs 132.1µs 7228. 273.79KB 40.9
#> 7 bracket 1000 10 77.2µs 85.4µs 11335. 47.52KB 19.9
#> 8 which 1000 10 67.8µs 75.2µs 13073. 7.91KB 23.2
#> 9 subset 1000 10 84.7µs 107.5µs 9281. 59.38KB 18.8
#> 10 bracket 10000 10 130.2µs 169.1µs 5799. 469.4KB 52.2
#> 11 which 10000 10 75.1µs 96µs 10187. 78.23KB 17.4
#> 12 subset 10000 10 222.7µs 253µs 3810. 586.73KB 43.3
Plotting
ggplot2::autoplot() can be used to generate an informative default plot. This plot is colored by gc level (0, 1, or 2) and faceted by parameters (if any). By default it generates a beeswarm plot, however you can also specify other plot types (jitter, ridge, boxplot, violin). See ?autoplot.bench_mark for full details.
ggplot2::autoplot(results)
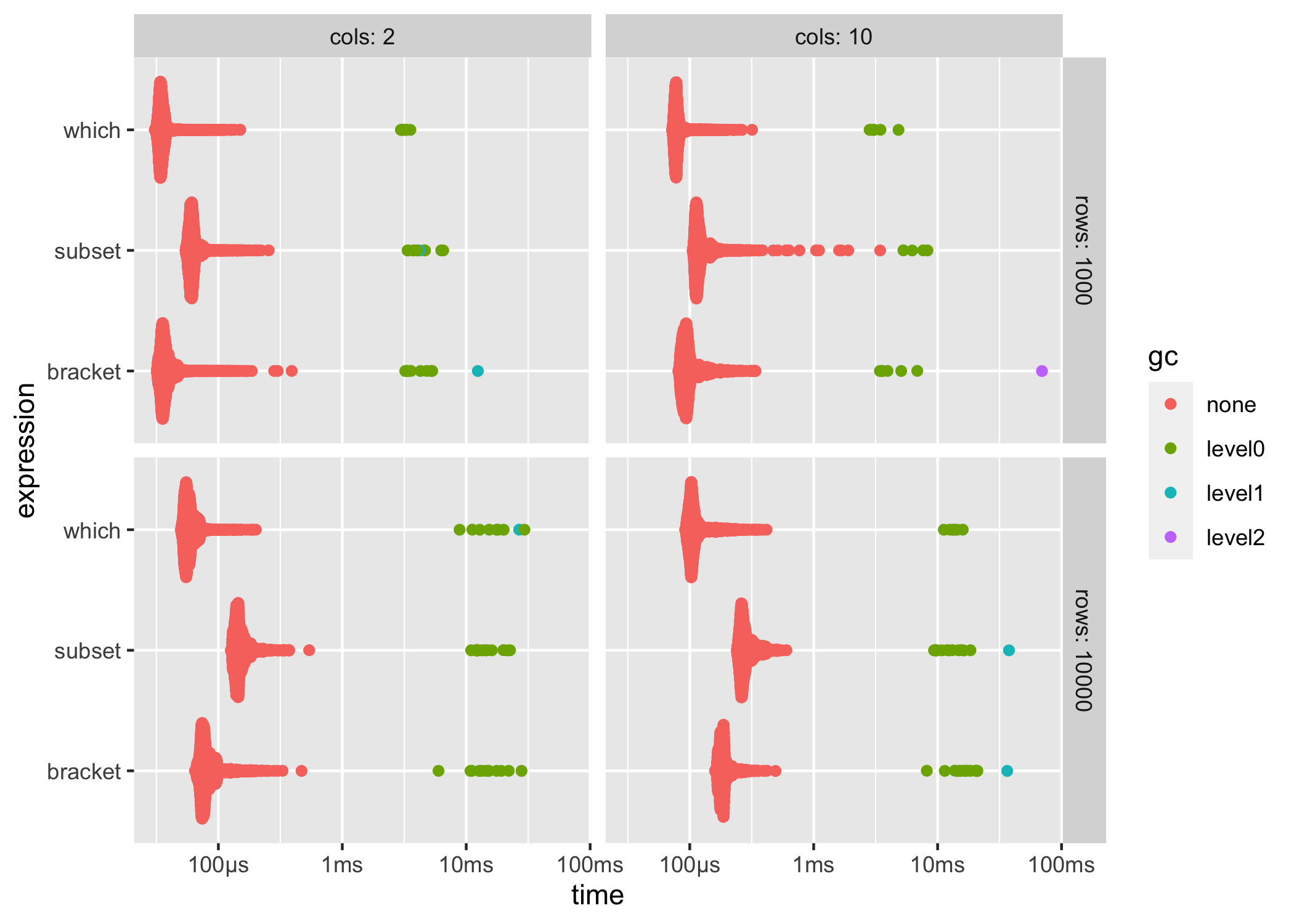
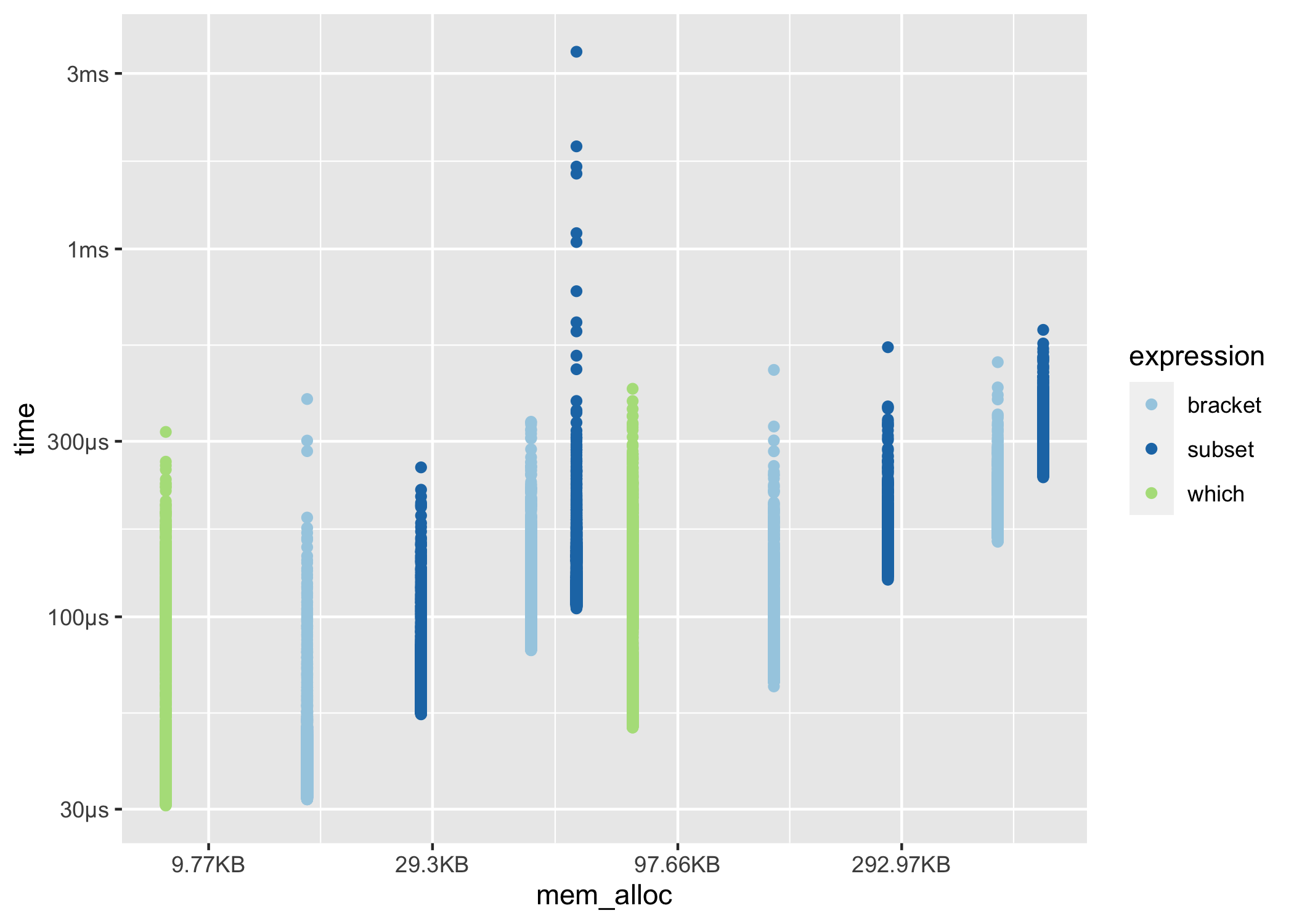
You can also produce fully custom plots by un-nesting the results and working with the data directly.
library(tidyverse)
results %>%
unnest(c(time, gc)) %>%
filter(gc == "none") %>%
mutate(expression = as.character(expression)) %>%
ggplot(aes(x = mem_alloc, y = time, color = expression)) +
geom_point() +
scale_color_bench_expr(scales::brewer_pal(type = "qual", palette = 3))
system_time()
bench also includes system_time(), a higher precision alternative to system.time().
bench::system_time({
i <- 1
while(i < 1e7) {
i <- i + 1
}
})
#> process real
#> 222ms 223ms
bench::system_time(Sys.sleep(.5))
#> process real
#> 88µs 502ms