Description
Distributed Representations of Sentences, Documents and Topics.
Description
Learn vector representations of sentences, paragraphs or documents by using the 'Paragraph Vector' algorithms, namely the distributed bag of words ('PV-DBOW') and the distributed memory ('PV-DM') model. The techniques in the package are detailed in the paper "Distributed Representations of Sentences and Documents" by Mikolov et al. (2014), available at <doi:10.48550/arXiv.1405.4053>. The package also provides an implementation to cluster documents based on these embedding using a technique called top2vec. Top2vec finds clusters in text documents by combining techniques to embed documents and words and density-based clustering. It does this by embedding documents in the semantic space as defined by the 'doc2vec' algorithm. Next it maps these document embeddings to a lower-dimensional space using the 'Uniform Manifold Approximation and Projection' (UMAP) clustering algorithm and finds dense areas in that space using a 'Hierarchical Density-Based Clustering' technique (HDBSCAN). These dense areas are the topic clusters which can be represented by the corresponding topic vector which is an aggregate of the document embeddings of the documents which are part of that topic cluster. In the same semantic space similar words can be found which are representative of the topic. More details can be found in the paper 'Top2Vec: Distributed Representations of Topics' by D. Angelov available at <doi:10.48550/arXiv.2008.09470>.
README.md
doc2vec
This repository contains an R package allowing to build Paragraph Vector models also known as doc2vec models. You can train the distributed memory ('PV-DM') and the distributed bag of words ('PV-DBOW') models. Next to that, it also allows to build a top2vec model allowing to cluster documents based on these embeddings.
- doc2vec is based on the paper Distributed Representations of Sentences and DocumentsMikolov et al. while top2vec is based on the paper Distributed Representations of TopicsAngelov
- The doc2vec part is an Rcpp wrapper around https://github.com/hiyijian/doc2vec
- The package allows one
- to train paragraph embeddings (also known as document embeddings) on character data or data in a text file
- use the embeddings to find similar documents, paragraphs, sentences or words
- cluster document embeddings using top2vec
- Note. For getting word vectors in R: look at package https://github.com/bnosac/word2vec, details here, for Starspace embeddings: look at package https://github.com/bnosac/ruimtehol
Installation
- For regular users, install the package from your local CRAN mirror
install.packages("doc2vec") - For installing the development version of this package:
remotes::install_github("bnosac/doc2vec")
Look to the documentation of the functions
help(package = "doc2vec")
Example on doc2vec
- Take some data and standardise it a bit.
- Make sure it has columns doc_id and text
- Make sure that each text has less than 1000 words (a word is considered separated by a single space)
- Make sure that each text does not contain newline symbols
library(doc2vec)
library(tokenizers.bpe)
library(udpipe)
data(belgium_parliament, package = "tokenizers.bpe")
x <- subset(belgium_parliament, language %in% "dutch")
x <- data.frame(doc_id = sprintf("doc_%s", 1:nrow(x)),
text = x$text,
stringsAsFactors = FALSE)
x$text <- tolower(x$text)
x$text <- gsub("[^[:alpha:]]", " ", x$text)
x$text <- gsub("[[:space:]]+", " ", x$text)
x$text <- trimws(x$text)
x$nwords <- txt_count(x$text, pattern = " ")
x <- subset(x, nwords < 1000 & nchar(text) > 0)
- Build the model
## Low-dimensional model using DM, low number of iterations, for speed and display purposes
model <- paragraph2vec(x = x, type = "PV-DM", dim = 5, iter = 3,
min_count = 5, lr = 0.05, threads = 1)
str(model)
## List of 3
## $ model :<externalptr>
## $ data :List of 4
## ..$ file : chr "C:\\Users\\Jan\\AppData\\Local\\Temp\\Rtmpk9Npjg\\textspace_1c446bffa0e.txt"
## ..$ n : num 170469
## ..$ n_vocabulary: num 3867
## ..$ n_docs : num 1000
## $ control:List of 9
## ..$ min_count: int 5
## ..$ dim : int 5
## ..$ window : int 5
## ..$ iter : int 3
## ..$ lr : num 0.05
## ..$ skipgram : logi FALSE
## ..$ hs : int 0
## ..$ negative : int 5
## ..$ sample : num 0.001
## - attr(*, "class")= chr "paragraph2vec_trained"
## More realistic model
model <- paragraph2vec(x = x, type = "PV-DBOW", dim = 100, iter = 20,
min_count = 5, lr = 0.05, threads = 4)
- Get the embedding of the documents or words and get the vocabulary
embedding <- as.matrix(model, which = "words")
embedding <- as.matrix(model, which = "docs")
vocab <- summary(model, which = "docs")
vocab <- summary(model, which = "words")
- Get the embedding of specific documents / words or sentences.
sentences <- list(
sent1 = c("geld", "diabetes"),
sent2 = c("frankrijk", "koning", "proximus"))
embedding <- predict(model, newdata = sentences, type = "embedding")
embedding <- predict(model, newdata = c("geld", "koning"), type = "embedding", which = "words")
embedding <- predict(model, newdata = c("doc_1", "doc_10", "doc_3"), type = "embedding", which = "docs")
ncol(embedding)
## [1] 100
embedding[, 1:4]
## [,1] [,2] [,3] [,4]
## doc_1 0.05721277 -0.10298843 0.1089350 -0.03075439
## doc_10 0.09553983 0.05211980 -0.0513489 -0.11847925
## doc_3 0.08008177 -0.03324692 0.1563442 0.06585038
- Get similar documents or words when providing sentences, documents or words
nn <- predict(model, newdata = c("proximus", "koning"), type = "nearest", which = "word2word", top_n = 5)
nn
## [[1]]
## term1 term2 similarity rank
## 1 proximus telefoontoestellen 0.5357178 1
## 2 proximus belfius 0.5169221 2
## 3 proximus ceo 0.4839031 3
## 4 proximus klanten 0.4819543 4
## 5 proximus taal 0.4590944 5
##
## [[2]]
## term1 term2 similarity rank
## 1 koning ministerie 0.5615162 1
## 2 koning verplaatsingen 0.5484987 2
## 3 koning familie 0.4911003 3
## 4 koning grondwet 0.4871097 4
## 5 koning gedragen 0.4694150 5
nn <- predict(model, newdata = c("proximus", "koning"), type = "nearest", which = "word2doc", top_n = 5)
nn
## [[1]]
## term1 term2 similarity rank
## 1 proximus doc_105 0.6684639 1
## 2 proximus doc_863 0.5917463 2
## 3 proximus doc_186 0.5233522 3
## 4 proximus doc_620 0.4919243 4
## 5 proximus doc_862 0.4619178 5
##
## [[2]]
## term1 term2 similarity rank
## 1 koning doc_44 0.6686417 1
## 2 koning doc_45 0.5616031 2
## 3 koning doc_583 0.5379452 3
## 4 koning doc_943 0.4855201 4
## 5 koning doc_797 0.4573555 5
nn <- predict(model, newdata = c("doc_198", "doc_285"), type = "nearest", which = "doc2doc", top_n = 5)
nn
## [[1]]
## term1 term2 similarity rank
## 1 doc_198 doc_343 0.5522854 1
## 2 doc_198 doc_899 0.4902798 2
## 3 doc_198 doc_983 0.4847047 3
## 4 doc_198 doc_642 0.4829021 4
## 5 doc_198 doc_336 0.4674844 5
##
## [[2]]
## term1 term2 similarity rank
## 1 doc_285 doc_319 0.5318567 1
## 2 doc_285 doc_286 0.5100293 2
## 3 doc_285 doc_113 0.5056069 3
## 4 doc_285 doc_526 0.4840761 4
## 5 doc_285 doc_488 0.4805686 5
sentences <- list(
sent1 = c("geld", "frankrijk"),
sent2 = c("proximus", "onderhandelen"))
nn <- predict(model, newdata = sentences, type = "nearest", which = "sent2doc", top_n = 5)
nn
## $sent1
## term1 term2 similarity rank
## 1 sent1 doc_742 0.4830917 1
## 2 sent1 doc_151 0.4340138 2
## 3 sent1 doc_825 0.4263285 3
## 4 sent1 doc_740 0.4059283 4
## 5 sent1 doc_776 0.4024554 5
##
## $sent2
## term1 term2 similarity rank
## 1 sent2 doc_105 0.5497447 1
## 2 sent2 doc_863 0.5061581 2
## 3 sent2 doc_862 0.4973840 3
## 4 sent2 doc_620 0.4793786 4
## 5 sent2 doc_186 0.4755909 5
sentences <- strsplit(setNames(x$text, x$doc_id), split = " ")
nn <- predict(model, newdata = sentences, type = "nearest", which = "sent2doc", top_n = 5)
Example on top2vec
Top2vec clusters document semantically and finds most semantically relevant terms for each topic
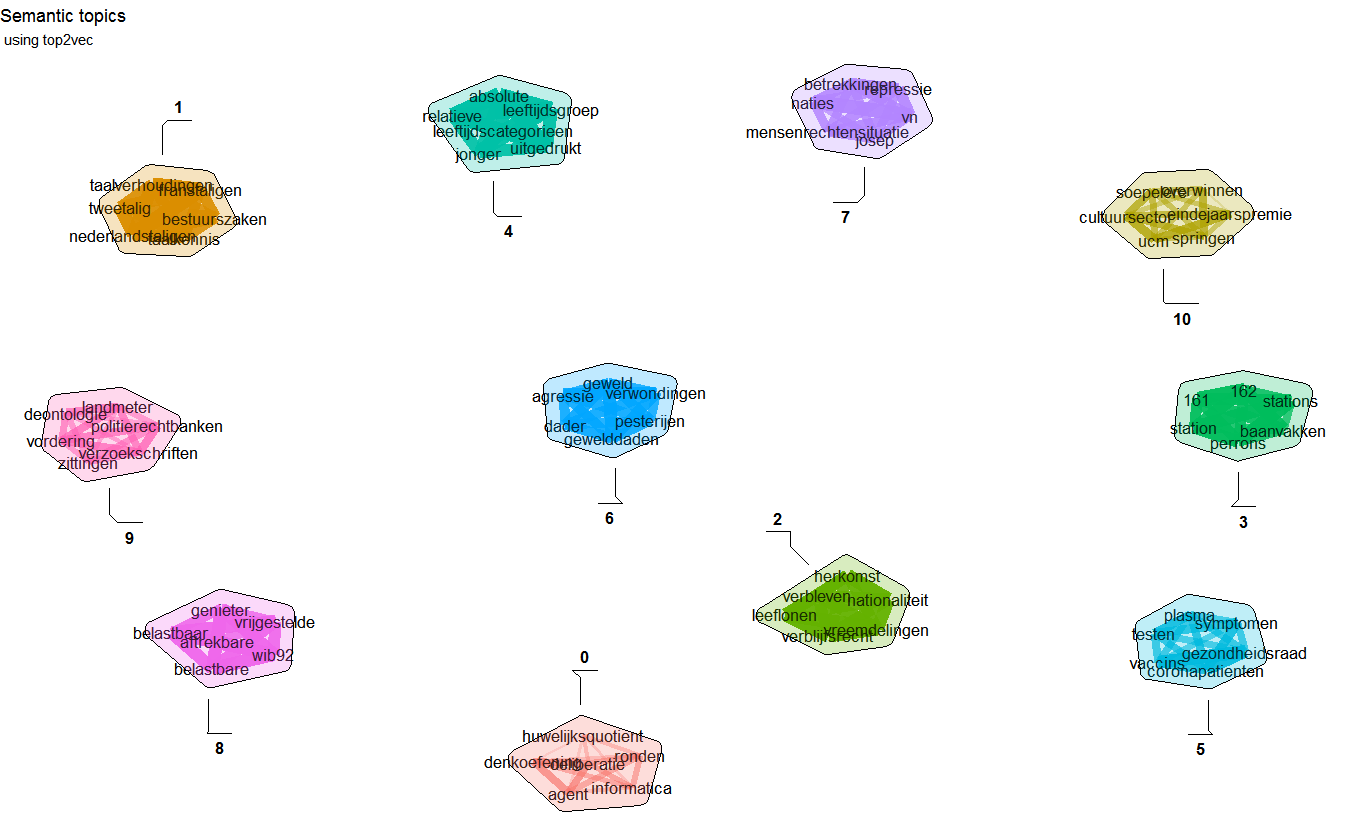
library(doc2vec)
library(word2vec)
library(uwot)
library(dbscan)
data(be_parliament_2020, package = "doc2vec")
x <- data.frame(doc_id = be_parliament_2020$doc_id,
text = be_parliament_2020$text_nl,
stringsAsFactors = FALSE)
x$text <- txt_clean_word2vec(x$text)
x <- subset(x, txt_count_words(text) < 1000)
d2v <- paragraph2vec(x, type = "PV-DBOW", dim = 50,
lr = 0.05, iter = 10,
window = 15, hs = TRUE, negative = 0,
sample = 0.00001, min_count = 5,
threads = 1)
model <- top2vec(d2v,
control.dbscan = list(minPts = 50),
control.umap = list(n_neighbors = 15L, n_components = 3), umap = tumap,
trace = TRUE)
info <- summary(model, top_n = 7)
info$topwords
Note
The package has some hard limits namely
- Each document should contain less than 1000 words
- Each word has a maximum length of 100 letters
Support in text mining
Need support in text mining? Contact BNOSAC: http://www.bnosac.be.