Description
Quality Control for Label-Free Proteomics Expression Data.
Description
Label-free bottom-up proteomics expression data is often affected by data heterogeneity and missing values. Normalization and missing value imputation are commonly used techniques to address these issues and make the dataset suitable for further downstream analysis. This package provides an optimal combination of normalization and imputation methods for the dataset. The package utilizes three normalization methods and three imputation methods.The statistical evaluation measures named pooled co-efficient of variance, pooled estimate of variance and pooled median absolute deviation are used for selecting the best combination of normalization and imputation method for the given dataset. The user can also visualize the results by using various plots available in this package. The user can also perform the differential expression analysis between two sample groups with the function included in this package. The chosen three normalization methods, three imputation methods and three evaluation measures were chosen for this study based on the research papers published by Välikangas et al. (2016) <doi:10.1093/bib/bbw095>, Jin et al. (2021) <doi:10.1038/s41598-021-81279-4> and Srivastava et al. (2023) <doi:10.2174/1574893618666230223150253>.This work has published by Sakthivel et al. (2025) <doi:10.1021/acs.jproteome.4c00552>.
README.md
About
The goal of lfproQC R package is to provide an optimal combination of normalization and imputation methods for the label-free proteomics expression dataset.
Installation
You can install the development version of lfproQC from GitHub with:
# install.packages("devtools")
devtools::install_github("kabilansbio/lfproQC", build_manual = TRUE, build_vignette = TRUE)
Example
This is a basic example for finding the best combinations of normalization and imputation method for the label-free proteomics expression dataset:
library(lfproQC)
## basic example code with the example dataset and data groups
yeast <- best_combination(yeast_data, yeast_groups, data_type = "Protein")
yeast$`Best combinations`
#> PCV_best_combination PEV_best_combination PMAD_best_combination
#> 1 rlr_knn, rlr_lls vsn_lls rlr_lls
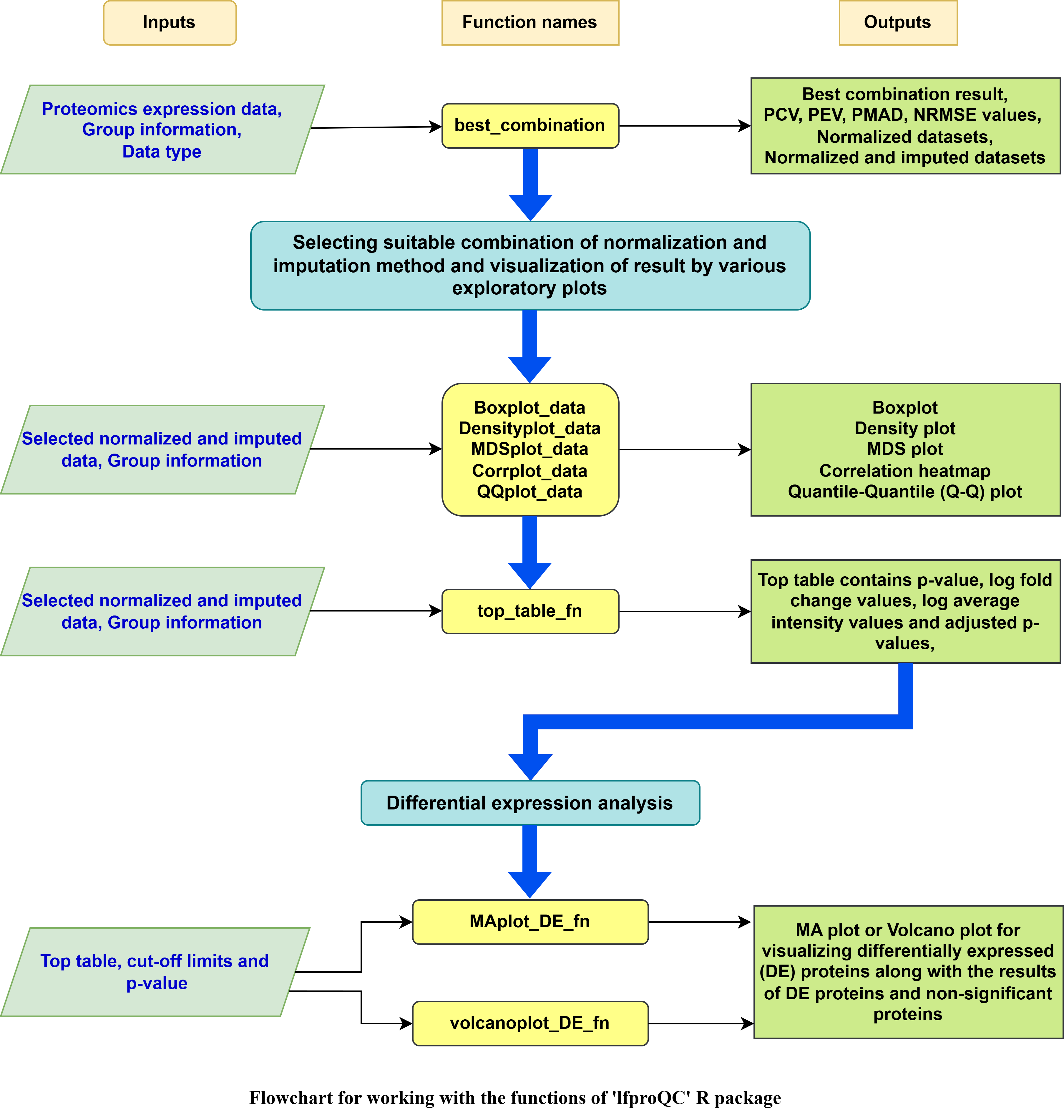
The overall workflow for using the ‘lfproQC’ package.