PH/MAP Parameter Estimation.
mapfit
![]()
![]()
The goal of mapfit is to estimate parameters of phase-type distribution (PH) and Markovian arrival process (MAP). PH/MAP fitting is required in the analysis of non-Markovian models involving general distributions. By replacing general distributions with estimated PH/MAP, we can approximate the non-Markovian models with continuous-time Markov chains (CTMCs). Our tool offers
- PH/MAP fitting with grouped data
- PH fitting with theoretical probability density functions.
These features help us to analyze non-Markovian models with phase expansion.
Installation
# Install devtools from CRAN
install.packages("mapfit")
# Or the development version from GitHub:
# install.packages("devtools")
devtools::install_github("okamumu/mapfit")
PH Fitting
Overview
PH distribution is defined as the time to absorption in a time-homogeneous CTMC with an absorbing state. The p.d.f. and cumulative distribution function (c.d.f.) are mathematically given as the expressions using matrix exponential. Let and
denote a probability (row) vector for determining an initial state and an infinitesimal generator for transient states, respectively. Since the c.d.f. is given by the probability that the current state of underlying CTMC has already been absorbed, the c.d.f. of PH distribution is given by
where is a column vector whose entries are 1. Also the p.d.f. can be obtained by taking the first derivative of the c.d.f.;
where .
The purpose of PH fitting is to determine PH parameters and
so that the estimated PH distribution fits to observed data. There are two different approaches; MM (moment match) method and MLE (maximum likelihood estimation). The MM method is to find PH parameters whose first few moments match to the moments from empirical data or distribution functions. On the other hand, MLE is to find PH parameters maximizing the likelihood (probability) of which the data is drawn from the model as a sample.
Data for PH fitting
The parameter estimation algorithm generally depends on data forms to be used. mapfit deals with several kinds of data in PH fitting; point data, weighted point data, grouped data, grouped data with missing values and truncated data. The point data consists of independent and identically-distributed (IID) random samples.
| Sample No. | Time |
|---|---|
| 1 | 10.0 |
| 2 | 1.4 |
| … | … |
| 100 | 51.0 |
The above table shows an example of point data for a hundred IID samples. The weighted point data is the point data in which all points have their own weights. The weighted point data is used for numerical integration of a density function in our tool. The grouped data consists of break points and counts. For each of two successive break points, the number of samples is counted as a bin. This is equivalent to the data format to draw a histogram.
The grouped data with missing values allows us to use the grouped data in which several counts are unknown (missing). In the tool, missing counts are expressed by NA. Also, in the truncated data, several samples are truncated at a point before their observations (right censored data). The truncated data can be represented as the number of samples in a specific interval from the point to infinity in the context of grouped data.
| Time interval | Counts |
|---|---|
| [0, 10] | 1 |
| [10, 20] | NA |
| [20, 30] | 4 |
| [30, 40] | 10 |
| [40, 50] | NA |
| [50, 60] | 30 |
| [60, 70] | 10 |
| [70, 80] | 12 |
| [80, 90] | 4 |
| [90, 100] | 0 |
| [100, Inf) | 5 |
The above table shows an example of the grouped data on break points 0, 10, 20, …, 100 where the data has missing values at the intervals [10,20] and [40,50]. Furthermore, the last 5 samples are truncated at 100.
| Time interval | Counts |
|---|---|
| [0, 10] | 1 |
| [10, 20] | NA |
| [20, 30] | 4 |
| [30, 40] | 10 |
| [40, 50] | NA |
| [50, 60] | 30 |
| [60, 70] | 10 |
| [70, 80] | 12 |
| [80, 90] | 4 |
| [90, 100] | 0 |
| [100, Inf) | NA |
On the other hand, the above table shows an example of another grouped data. In this case, several samples are truncated at 100 but we do not know the exact number of truncated samples.
Models and Methods
PH distributions are classified to sub-classes by the structure of and
, and the parameter estimation algorithms depend on the class of PH distribution. The tool deals with the following classes of PH distribution:
- general PH: The PH distribution in which there are no constraints on
and
. In the tool, this is referred to as `ph’ class.
- canonical form 1 (CF1): One of the minimal representations of acyclic PH distribution. The matrix
- hyper-Erlang distribution: One of the representations of acyclic PH distribution. The distribution consists of a mixture of Erlang distributions. In the tool, this is referred to as `herlang’ class.
The parameters of ph class are ,
and
, which are defined as members of R6 class in R. To represent the matrix
, we use
Matrix package which is an external package of R. The cf1 class are inherited from the ph class. In addition to inherited members, cf1 has a member rate to store the absolute values of diagonal elements of . The
herlang class has the member for the mixed ratio as alpha, shape parameters of Erlang components shape, rate parameters of Erlang components rate. herlang classes can be transformed to ph class by using as.gph method of R. cf1 has members for alpha, Q and xi.
The R functions for PH parameter estimation are;
phfit.point: MLEs for general PH, CF1 and hyper-Erlang distribution from point and weighted point data. The estimation algorithms for general PH and CF1 are the EM algorithms proposed in [1]. The algorithm for hyper-Erlang distribution is the EM algorithm with shape parameter selection described in [2,3].phfit.group: MLEs for general PH, CF1 and hyper-Erlang distribution from grouped and truncated data. The estimation algorithms for general PH and CF1 are the EM algorithms proposed in [4]. The algorithm for hyper-Erlang distribution is the EM algorithm with shape parameter selection, which is originally developed as an extension of [2,3].phfit.density: MLEs for general PH, CF1 and hyper-Erlang distribution from a density function defined on the positive domain [0, Inf). The functionphfit.densitycallsphfit.pointafter making weighted point data. The weighted point data is generated by numerical quadrature. In the tool, the numerical quadrature is performed with a double exponential (DE) formula.phfit.3mom: MM methods for acyclic PH distribution with the first three moments [5,6].
The functions phfit.point, phfit.group and phfit.density select an appropriate algorithm depending on the class of a given PH distribution. These functions return a list including the estimated model (ph, cf1 or herlang), the maximum log-likelihood (llf), Akaike information criterion (aic) and other statistics of the estimation algorithm. Also, the function phfit.3mom returns a ph class whose first three moments match to the given three moments.
Example
Here we introduce examples of the usage of PH fitting based on IID samples from Weibull distribution. At first, we load the mapfit package and generate IID samples from a Weibull distribution:
library(mapfit)
RNGkind(kind = "Mersenne-Twister")
set.seed(1234)
wsample <- rweibull(100, shape=2, scale=1)
wsample is set to a vector including a hundred IID samples generated from Weibull distribution with scale parameter 1 and shape parameter 2. set.seed(1234) means determining the seed of random numbers.
wsample
#> [1] 1.47450394 0.68871906 0.70390766 0.68745901 0.38698715 0.66768398
#> [7] 2.15798755 1.20774494 0.63744792 0.81550201 0.60487388 0.77911210
#> [13] 1.12394405 0.28223484 1.10901777 0.42140013 1.11847354 1.14942511
#> [19] 1.29542664 1.20832306 1.07241633 1.09317655 1.35593576 1.79415102
#> [25] 1.23272029 0.45823831 0.80189104 0.29867185 0.42977942 1.75616647
#> [31] 0.88603717 1.15209430 1.09019210 0.82379560 1.30718279 0.52428076
#> [37] 1.26618210 1.16260990 0.08877248 0.46259605 0.76928163 0.66055079
#> [43] 1.07949774 0.68927927 1.05326127 0.83015673 0.62445527 0.85066119
#> [49] 1.18780419 0.51698994 1.61451826 1.08267929 0.57645512 0.82710123
#> [55] 1.37015479 0.82783512 0.83982074 0.53486736 1.32097400 0.40547750
#> [61] 0.38107465 1.78142911 1.07157783 2.07043978 1.19632106 0.58944015
#> [67] 1.08505663 0.82231170 1.72143270 0.75610263 1.45189672 0.33667780
#> [73] 2.05544853 0.49443698 1.55189411 0.80962054 0.97796650 1.63049390
#> [79] 1.06650011 0.63460678 0.27649350 0.86658386 1.39556590 0.77994249
#> [85] 1.27622488 0.32701528 0.97102624 1.08091533 1.35366256 0.33107018
#> [91] 1.33917815 0.32386549 1.41750912 1.42403682 1.50035348 0.81868450
#> [97] 1.09695465 1.90327589 1.08273771 0.54611792
Based on the point data, we can estimate PH parameters. Here we obtain the estimated parameters for general PH with 5 states, CF1 with 5 states and the hyper-Erlang with 5 states by the following commands, respectively;
## phfit with GPH
phfit.point(ph=ph(5), x=wsample)
#>
#> Maximum LLF: -59.436999
#> DF: 29
#> AIC: 176.873999
#> Iteration: 2000 / 2000
#> Computation time (user): 1.978000
#> Convergence: FALSE
#> Error (abs): 2.658413e-05 (tolerance Inf)
#> Error (rel): 4.472655e-07 (tolerance 1.490116e-08)
#>
#> Size : 5
#> Initial : 8.381857e-11 0.9958299 0.000605489 0.003564639 1.026552e-94
#> Exit : 0.1181382 4.427337e-93 6.467791e-06 0.05122773 4.831366
#> Infinitesimal generator :
#> 5 x 5 sparse Matrix of class "dgCMatrix"
#>
#> [1,] -4.871478e+00 5.176939e-144 1.738194e-66 5.793350e-18 4.75334026
#> [2,] 6.288755e-02 -4.830630e+00 4.592414e+00 8.770330e-03 0.16655846
#> [3,] 1.237500e-04 9.821536e-18 -4.850766e+00 4.816661e+00 0.03397468
#> [4,] 4.455372e+00 3.303485e-66 8.839500e-21 -4.846094e+00 0.33949432
#> [5,] 4.440043e-15 4.269800e-225 4.149348e-124 9.632575e-51 -4.83136581
## phfit with CF1
phfit.point(ph=cf1(5), x=wsample)
#> Initializing CF1 ...
#> oxxxxx
#> xxxxxx
#> xxxxxx
#> xxxxxx
#> xxxxxx
#> xxxxxx
#>
#> Maximum LLF: -59.416058
#> DF: 9
#> AIC: 136.832116
#> Iteration: 2000 / 2000
#> Computation time (user): 1.731000
#> Convergence: FALSE
#> Error (abs): 1.497201e-06 (tolerance Inf)
#> Error (rel): 2.519859e-08 (tolerance 1.490116e-08)
#>
#> Size : 5
#> Initial : 0.8888711 0.003245776 0.08347344 0.02440971 9.387039e-102
#> Rate : 4.830947 4.830966 4.88052 4.880523 4.880526
## phfit with Hyper-Erlang
phfit.point(ph=herlang(5), x=wsample, ubound=3)
#> shape: 1 1 3 llf=-62.78
#> shape: 1 2 2 llf=-71.80
#> shape: 1 4 llf=-60.08
#> shape: 2 3 llf=-62.78
#> shape: 5 llf=-61.37
#>
#> Maximum LLF: -60.083945
#> DF: 4
#> AIC: 128.167889
#> Iteration: 205 / 2000
#> Computation time (user): 0.010000
#> Convergence: TRUE
#> Error (abs): 8.852490e-07 (tolerance Inf)
#> Error (rel): 1.473354e-08 (tolerance 1.490116e-08)
#>
#> Size : 2
#> Shape : 1 4
#> Initial : 0.01005939 0.9899406
#> Rate : 3.799481 4.058378
In the above example, the number of Erlang components is restructured to 3 or less by using ubound argument (see [2] in detail).
Also we present PH fitting with grouped data. In this example, we make grouped data from the point data wsample by using the function hist which is originally a function to draw a histogram.
h.res <- hist(wsample, breaks="fd", plot=FALSE)
h.res$breaks
#> [1] 0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6 1.8 2.0 2.2
h.res$counts
#> [1] 1 9 12 14 15 20 13 6 6 1 3
In the above, breaks are determined according to Freedman-Diaconis (FD) rule. Then we can get estimated PH parameters from grouped data.
## phfit with GPH
phfit.group(ph=ph(5), counts=h.res$counts, breaks=h.res$breaks)
#>
#> Maximum LLF: -22.812530
#> DF: 29
#> AIC: 103.625059
#> Iteration: 1648 / 2000
#> Computation time (user): 0.355000
#> Convergence: TRUE
#> Error (abs): 3.396318e-07 (tolerance Inf)
#> Error (rel): 1.488795e-08 (tolerance 1.490116e-08)
#>
#> Size : 5
#> Initial : 8.191206e-08 1.395077e-64 0.9998728 0.0001250616 2.092792e-06
#> Exit : 8.185605e-06 4.88599 1.973519e-65 1.476447e-07 0.0001568522
#> Infinitesimal generator :
#> 5 x 5 sparse Matrix of class "dgCMatrix"
#>
#> [1,] -4.716760e+00 1.283349e-01 1.569076e-19 9.129134e-05 4.588326e+00
#> [2,] 8.528916e-123 -4.885990e+00 4.786686e-205 1.550664e-20 7.924260e-58
#> [3,] 4.349205e+00 3.927403e-03 -4.886069e+00 5.329321e-01 5.000110e-06
#> [4,] 1.528398e-55 4.846790e+00 8.559353e-115 -4.846790e+00 8.307741e-17
#> [5,] 6.936069e-20 2.830921e-05 1.273236e-61 4.685313e+00 -4.685498e+00
## phfit with CF1
phfit.group(ph=cf1(5), counts=h.res$counts, breaks=h.res$breaks)
#> Initializing CF1 ...
#> oxxxxx
#> xxxxxx
#> xxxxxx
#> xxxxxx
#> xxxxxx
#> xxxxxx
#>
#> Maximum LLF: -22.811905
#> DF: 9
#> AIC: 63.623811
#> Iteration: 1300 / 2000
#> Computation time (user): 0.256000
#> Convergence: TRUE
#> Error (abs): 3.388332e-07 (tolerance Inf)
#> Error (rel): 1.485335e-08 (tolerance 1.490116e-08)
#>
#> Size : 5
#> Initial : 0.8667713 2.82726e-05 0.1323529 0.0008475288 9.382448e-58
#> Rate : 4.684116 4.684117 4.886013 4.886015 4.886017
## phfit with Hyper-Erlang
phfit.group(ph=herlang(5), counts=h.res$counts, breaks=h.res$breaks)
#> shape: 1 1 1 1 1 llf=-61.14
#> shape: 1 1 1 2 llf=-35.55
#> shape: 1 1 3 llf=-26.45
#> shape: 1 2 2 llf=-35.55
#> shape: 1 4 llf=-23.59
#> shape: 2 3 llf=-26.45
#> shape: 5 llf=-23.97
#>
#> Maximum LLF: -23.588309
#> DF: 4
#> AIC: 55.176618
#> Iteration: 204 / 2000
#> Computation time (user): 0.012000
#> Convergence: TRUE
#> Error (abs): 3.487320e-07 (tolerance Inf)
#> Error (rel): 1.478410e-08 (tolerance 1.490116e-08)
#>
#> Size : 2
#> Shape : 1 4
#> Initial : 0.002267855 0.9977321
#> Rate : 3.185279 4.059259
Next we present the case where PH parameters are estimated from a density function. The density function of Weibull distribution is given by a function dweibull. Then we can also execute the following commands;
## phfit with GPH
phfit.density(ph=ph(5), f=dweibull, shape=2, scale=1)
#>
#> Maximum LLF: -11.277901
#> DF: 29
#> KL: 0.003678
#> Iteration: 2000 / 2000
#> Computation time (user): 2.199000
#> Convergence: FALSE
#> Error (abs): 4.373887e-05 (tolerance Inf)
#> Error (rel): 3.878266e-06 (tolerance 1.490116e-08)
#>
#> Size : 5
#> Initial : 0.002418179 9.821622e-10 3.600447e-10 0.9975812 5.963473e-07
#> Exit : 2.100892e-07 4.481721 0.009147137 1.348414e-09 2.014541e-06
#> Infinitesimal generator :
#> 5 x 5 sparse Matrix of class "dgCMatrix"
#>
#> [1,] -7.678954e+00 6.065494e+00 5.807125e-17 7.860962e-58 1.613460e+00
#> [2,] 2.015246e-16 -4.481721e+00 4.065456e-53 1.472027e-113 1.949072e-19
#> [3,] 5.737140e-01 6.334776e-05 -4.359790e+00 8.547004e-21 3.776866e+00
#> [4,] 2.235419e-05 6.215926e-01 3.859707e+00 -4.481354e+00 3.184373e-05
#> [5,] 5.565411e+00 1.398323e+00 1.308304e-14 2.552571e-53 -6.963736e+00
## phfit with CF1
phfit.density(ph=cf1(5), f=dweibull, shape=2, scale=1)
#> Initializing CF1 ...
#> oxxxxx
#> xxxxxx
#> xxxxxx
#> xxxxxx
#> xxxxxx
#> xxxxxx
#>
#> Maximum LLF: -11.247613
#> DF: 9
#> KL: 0.002069
#> Iteration: 2000 / 2000
#> Computation time (user): 1.586000
#> Convergence: FALSE
#> Error (abs): 2.767693e-07 (tolerance Inf)
#> Error (rel): 2.460694e-08 (tolerance 1.490116e-08)
#>
#> Size : 5
#> Initial : 0.7536251 0.002987832 0.1516952 0.09169184 2.131364e-37
#> Rate : 4.844488 4.844509 5.062465 5.06247 5.062475
## phfit with Hyper-Erlang
phfit.density(ph=herlang(5), f=dweibull, shape=2, scale=1)
#> shape: 1 1 1 1 1 llf=-16.55
#> shape: 1 1 1 2 llf=-12.44
#> shape: 1 1 3 llf=-11.48
#> shape: 1 2 2 llf=-12.44
#> shape: 1 4 llf=-11.39
#> shape: 2 3 llf=-11.51
#> shape: 5 llf=-12.83
#>
#> Maximum LLF: -11.391140
#> DF: 4
#> KL: 0.009694
#> Iteration: 77 / 2000
#> Computation time (user): 0.012000
#> Convergence: TRUE
#> Error (abs): 1.461348e-07 (tolerance Inf)
#> Error (rel): 1.282881e-08 (tolerance 1.490116e-08)
#>
#> Size : 2
#> Shape : 1 4
#> Initial : 0.07425929 0.9257407
#> Rate : 2.132549 4.349237
The last two arguments for each execution are parameters of dweibull function. User-defined functions are also used as density functions in similar manner.
Usually, the PH fitting with density is used for the PH expansion (PH approximation) in which known general distributions are replaced with the PH distributions estimated from these density functions. Compared to PH fitting with samples, PH fitting with density function tends to be accurate, because density function has more information than samples. Therefore, in the case of PH fitting with density function, we can treat PH distributions with high orders without causing overfitting, i.e., it is possible to perform PH fitting even if PH has 100 states;
## estimate PH parameters from the density function
(result.density <- phfit.density(ph=cf1(100), f=dweibull, shape=2, scale=1))
#> Initializing CF1 ...
#> ooooxx
#> xxxxox
#> xxoxxx
#> xxoxxx
#> xxxxxx
#> xxxxxx
#>
#> Maximum LLF: -11.208676
#> DF: 199
#> KL: 0.000000
#> Iteration: 40 / 2000
#> Computation time (user): 0.402000
#> Convergence: TRUE
#> Error (abs): 1.596614e-07 (tolerance Inf)
#> Error (rel): 1.424445e-08 (tolerance 1.490116e-08)
#>
#> Size : 100
#> Initial : 0.0001817557 0.0002199945 0.0002849414 0.0003823432 0.0005203138 0.0007081901 0.0009555305 0.001271161 0.001662378 0.00213446 0.002690543 0.003331824 0.004057922 0.004867224 0.005757032 0.006723475 0.007761197 0.008862959 0.01001928 0.01121831 0.01244589 0.01368604 0.01492163 0.01613516 0.01730967 0.01842943 0.01948053 0.02045124 0.02133205 0.0221157 0.02279694 0.02337235 0.02384012 0.02419988 0.02445255 0.02460023 0.02464612 0.02459445 0.02445036 0.02421979 0.02390929 0.02352592 0.02307703 0.02257007 0.02201249 0.02141157 0.0207743 0.02010733 0.01941691 0.01870884 0.01798851 0.01726081 0.01653022 0.01580077 0.01507609 0.01435938 0.01365348 0.01296082 0.01228352 0.01162334 0.01098173 0.01035988 0.009758688 0.009178828 0.00862076 0.008084756 0.007570922 0.007079222 0.006609496 0.006161481 0.005734828 0.005329111 0.004943847 0.004578498 0.004232485 0.00390519 0.003595963 0.003304128 0.003028987 0.002769832 0.002525954 0.002296659 0.002081281 0.001879196 0.001689827 0.001512641 0.00134713 0.001192767 0.001048963 0.0009150229 0.0007901335 0.0006734343 0.0005642032 0.0004621629 0.0003677834 0.0002822111 0.0002060518 0.0001355869 5.772149e-05 9.89152e-07
#> Rate : 12.48094 13.67933 14.7307 15.64476 16.4295 17.09579 17.65842 18.13518 18.54521 18.90725 19.23834 19.55306 19.86316 20.17759 20.50277 20.84294 21.20065 21.57721 21.97308 22.38825 22.82253 23.2757 23.74767 24.23853 24.74852 25.27808 25.82772 26.39805 26.98969 27.60327 28.23941 28.89869 29.58167 30.28889 31.0209 31.77823 32.56147 33.37118 34.20799 35.07256 35.96555 36.8877 37.83973 38.82243 39.83658 40.883 41.96254 43.07605 44.22444 45.40861 46.62951 47.8881 49.18539 50.5224 51.9002 53.31989 54.78258 56.28945 57.84169 59.44054 61.08725 62.78316 64.52958 66.32792 68.17958 70.08605 72.04881 74.06944 76.14951 78.29068 80.49462 82.76309 85.09788 87.50081 89.97379 92.51877 95.13775 97.83278 100.606 103.4596 106.3957 109.4168 112.5251 115.7231 119.0133 122.3984 125.8809 129.4637 133.1495 136.9412 140.8417 144.854 148.9813 153.2266 157.5935 162.0854 166.7062 171.4588 176.3446 181.3698
The result provides a highly-accurate approximation for Weibull distribution. However, from the viewpoint of computation time, it should be noted that only cf1 or herlang with lower/upper bounds of Erlang components can be applied to PH fitting with high orders. In the above example, although the number of states is 100, the execution time is in a few seconds because of the refinement of EM algorithm [1].
If we use only point data to estimate PH parameters with high orders, the overfitting is happen.
## estimate PH parameters from 100 samples (overfitting example)
(result.point <- phfit.point(ph=cf1(100), x=wsample))
#> Initializing CF1 ...
#> oooxxx
#> xxxxxx
#> xxxxxx
#> xxxxxx
#> xxxxxx
#> xxxxxx
#>
#> Maximum LLF: -50.504606
#> DF: 185
#> AIC: 471.009213
#> Iteration: 2000 / 2000
#> Computation time (user): 14.520000
#> Convergence: FALSE
#> Error (abs): 2.196319e-05 (tolerance Inf)
#> Error (rel): 4.348748e-07 (tolerance 1.490116e-08)
#>
#> Size : 100
#> Initial : 0.1202048 6.679923e-05 9.145549e-07 6.718388e-06 0.001283871 0.02800786 0.01171954 0.008940903 0.315099 0.02227029 9.221007e-08 1.84297e-19 3.756857e-38 3.874537e-62 9.20175e-87 6.878353e-105 2.853375e-109 1.005652e-96 4.503625e-71 2.928074e-41 9.505794e-17 0.00179272 0.2276657 0.001248857 6.610175e-08 7.619455e-13 3.954642e-17 9.383904e-20 3.348167e-20 1.573251e-18 1.97383e-15 1.610638e-11 1.036936e-07 0.0001142191 0.009129112 0.04846457 0.0305252 0.005057544 0.0005268339 7.985494e-05 3.378966e-05 5.432951e-05 0.0002907046 0.00286521 0.01997708 0.03347203 0.005724726 6.916916e-05 9.08789e-08 5.294994e-11 1.25534e-13 1.402524e-14 4.047361e-13 2.399657e-09 0.0001240435 0.09399483 0.001188389 1.702627e-12 2.27337e-31 2.12508e-63 1.579558e-111 1.528505e-178 4.946943e-267 4.940656e-324 4.940656e-324 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 3.800888e-310 2.98257e-133 1.016015e-28 0.01 2.112341e-52 1.324818e-170 4.940656e-324 0 0 0 0 0 0 0 0 0 0 0
#> Rate : 13.72962 13.72962 13.72963 13.72963 13.77239 14.08349 14.08361 14.08422 33.20377 33.20423 33.20469 33.20493 33.20497 33.20527 33.20535 33.20586 33.20637 33.69793 34.45626 35.48529 37.38158 51.33875 68.41158 68.4116 68.41161 68.41167 68.4117 68.4118 68.41188 68.41188 68.41188 68.49642 68.65949 69.16467 71.61702 74.8835 75.04758 75.04761 75.04777 75.11004 75.2494 75.4362 75.7301 76.4299 78.24315 79.50126 79.5141 79.67761 79.90004 80.1526 80.4383 80.77559 81.2235 82.03581 85.49975 115.0783 115.0783 115.0784 115.0785 115.4152 115.809 116.232 116.6771 117.1402 117.6191 118.112 118.6178 119.1356 119.6647 120.2044 120.7543 121.3138 121.8827 122.4606 123.0475 123.6434 124.2487 124.8639 125.4901 126.1293 126.7854 127.4669 128.1977 129.0762 131.115 165.2486 165.3993 165.6066 165.8337 166.0713 166.3163 166.5671 166.823 167.0835 167.3481 167.6166 167.8888 168.1646 168.444 168.727
## 3 moments match
m1 <- gamma(1+1/2)
m2 <- gamma(1+2/2)
m3 <- gamma(1+3/2)
(result.3mom <- phfit.3mom(m1, m2, m3))
#> Size : 6
#> Initial : 0.8760898 0 0 0 0 0.1239102
#> Exit : 0 0 0 0 0 3.535949
#> Infinitesimal generator :
#> 6 x 6 sparse Matrix of class "dgCMatrix"
#>
#> [1,] -7.259401 7.259401 . . . .
#> [2,] . -7.259401 7.259401 . . .
#> [3,] . . -7.259401 7.259401 . .
#> [4,] . . . -7.259401 7.259401 1.289529e-14
#> [5,] . . . . -7.259401 7.259401e+00
#> [6,] . . . . . -3.535949e+00
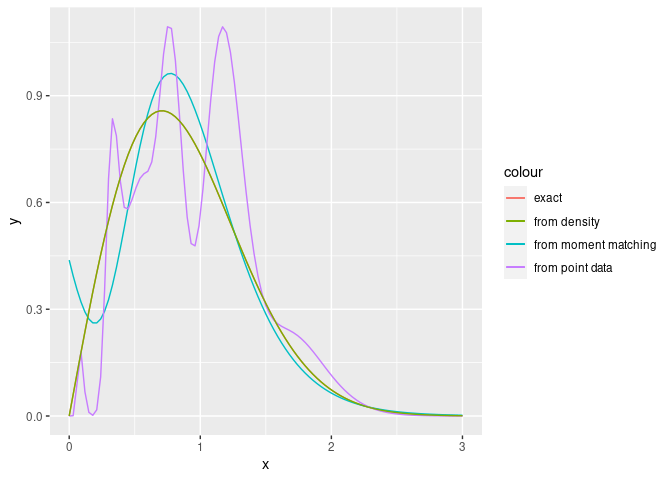
library(ggplot2)
ggplot(data.frame(x=seq(0, 3, length.out=100)), aes(x=x)) +
stat_function(fun=dweibull, args=list(shape=2, scale=1), aes_(colour='exact')) +
stat_function(fun=dphase, args=list(ph=result.3mom), aes_(colour='from moment matching')) +
stat_function(fun=dphase, args=list(ph=result.point$model), aes_(colour='from point data')) +
stat_function(fun=dphase, args=list(ph=result.density$model), aes_(colour='from density'))
References
- [1] H. Okamura, T. Dohi and K.S. Trivedi, A refined EM algorithm for PH distributions, Performance Evaluation, 68(10), 938-954, 2011.
- [2] A. Thummler and P. Buchholz and M. Telek, A novel approach for phase-type fitting with the EM algorithm, IEEE Transactions on Dependable and Secure Computing, 3(3), 245-258, 2006.
- [3] A. Panchenko and A. Thummler, Efficient phase-type fitting with aggregated traffic traces, Performance Evaluation, 64, 629-645, 2007.
- [4] H. Okamura, T. Dohi and K.S. Trivedi, Improvement of EM algorithm for phase-type distributions with grouped and truncated data, Applied Stochastic Models in Business and Industry, 29(2), 141-156, 2013.
- [5] A. Bobbio and A. Horvath and M. Telek, Matching three moments with minimal acyclic phase type distributions, Stochastic Models, 21(2/3), 303-326, 2005.
- [6] T. Osogami and M. Harchol-Balter, Closed form solutions for mapping general distributions to minimal PH distributions, Performance Evaluation, 63(6), 524-552, 2006.
MAP Fitting
Overview
MAP (Markovian arrival process) is a stochastic point process whose arrival rates are dominated by a CTMC. The CTMC expresses the internal state of MAP called a phase process. MAP is generally defined by an initial probability vector and two matrices for infinitesimal generators
,
. Let
be the row vector whose i-th entry is the probability that the phase process is i at time t and n arrivals occur before time t. Then we have the following differential equations:
where and
are infinitesimal generators of phase process without and with arrivals, respectively. Note that
becomes the infinitesimal generator of phase process. Similar to PH fitting, the purpose of MAP fitting is to find MAP parameters
,
and
so that the estimated MAP fits to observed data. In MAP fitting, there are also two approaches; MM method and MLE. The MM method for MAP is to determine MAP parameters with marginal/joint moments and k-lag correlation [1]. MLE is to find MAP parameters maximizing the log-likelihood function. We implement MLE approaches in the tool.
Data for MAP fitting
mapfit deals with point data and grouped data in MAP fitting. The point data for MAP fitting is a time series for arrivals. The grouped data for MAP fitting consists of break points and counts which are made from a time series for arrivals.
| Arrival No. | Time (sec) |
|---|---|
| 1 | 1.340 |
| 2 | 1.508 |
| 3 | 4.176 |
| 4 | 8.140 |
| 5 | 11.036 |
| 6 | 15.072 |
| 7 | 17.892 |
| 8 | 20.604 |
| 9 | 22.032 |
| 10 | 24.300 |
| … | … |
The above table shows an example of point data that consists of arrival times.
| Time interval | Counts |
|---|---|
| [0, 5] | 3 |
| [5, 10] | 1 |
| [10, 15] | 1 |
| [15, 20] | 2 |
| [20, 25] | 4 |
| … | … |
The above table shows an example of grouped data. The grouped data is made from the point data by counting the number of arrivals in every 5 seconds. Note that missing values cannot be treated in MAP fitting of this version of tool.
Models and Methods
mapfit has three classes (models) for MAP, which have different parameter estimation algorithms.
- general MAP: MAP with no constraint on parameters. This class is referred to as
mapin the tool. Also, the tool uses a Markov modulated Poisson process (MMPP) as a specific structure ofmap, which can be generated by anmmppcommand. - HMM (hidden Markov model) with Erlang outputs (ER-HMM): One of MAP representation where Erlang outputs correspond to time intervals between two successive arrivals [2]. In the tool, this class is referred to as
erhmm. - MMPP with grouped data: MMPP with approximate parameter estimation. This is referred to as
gmmppin the tool, and is essentially same asmmppexcept for parameter estimation algorithm. In the parameter estimation ofgmmpp, it is assumed that at most one phase change is allowed in one observed time interval [3].
The map class consists of parameters ,
and
, which are given by slots of S4 class in R. The
gmmpp class also has the slots alpha, D0 and D1 as model parameters. The erhmm class has an initial probability vector for HMM states (alpha), a probability transition matrix for HMM states (P), the shape parameters for Erlang distribution (shape) and the rate parameters for Erlang distribution (rate). The S4 class erhmm can be transformed to map by using as method.
The tool has the following MAP fitting functions:
mapfit.point: MLEs for general MAP and ER-HMM from point data. The estimation algorithm for general MAP is the EM algorithm introduced in [4]. The algorithm for ER-HMM is the EM algorithm proposed in [2].mapfit.group: MLEs for general MAP andgmmppfrom grouped data. Both the estimation algorithms for general MAP andgmmppare presented in [3]. Note thaterhmmcannot be used in the case of grouped data.
The functions mapfit.point and mapfit.group select an appropriate algorithm depending on the class of a given MAP. These functions return a list including the estimated model (map, erhmm or gmmpp), the maximum log-likelihood (llf), Akaike information criterion (aic) and other statistics of the estimation algorithm. In general, erhmm for point data and gmmpp for grouped data are much faster than general MAP.
Example
Here we demonstrate MAP fitting with point and grouped data. The data used in this example is the traffic data; BCpAug89, which consists of time intervals for packet arrivals and is frequently used in several papers as a benchmark. We use only the first 1000 arrival times.
RNGkind(kind = "Mersenne-Twister")
set.seed(1234)
data(BCpAug89)
BCpAug89
#> [1] 0.001340 0.000168 0.002668 0.003964 0.002896 0.004036 0.002820 0.002712
#> [9] 0.001428 0.002268 0.000452 0.002604 0.001336 0.002148 0.000768 0.004236
#> [17] 0.002624 0.004056 0.001520 0.001280 0.001972 0.001952 0.001112 0.001824
#> [25] 0.001636 0.002536 0.002688 0.003984 0.002872 0.004132 0.002728 0.003968
#> [33] 0.002888 0.004116 0.002744 0.004008 0.002848 0.004160 0.004340 0.003920
#> [41] 0.004580 0.004008 0.004492 0.003920 0.002940 0.004080 0.002780 0.003960
#> [49] 0.002896 0.001104 0.002836 0.000712 0.002208 0.000840 0.003172 0.000088
#> [57] 0.002756 0.003932 0.002928 0.004128 0.002732 0.004056 0.002800 0.004016
#> [65] 0.002844 0.003324 0.000620 0.002912 0.000956 0.003688 0.000360 0.003496
#> [73] 0.001436 0.002592 0.002832 0.001280 0.002688 0.002892 0.001432 0.001956
#> [81] 0.000576 0.001392 0.000888 0.001064 0.000144 0.001804 0.001956 0.000084
#> [89] 0.000156 0.001612 0.001248 0.001652 0.001756 0.000552 0.002900 0.004000
#> [97] 0.002856 0.003984 0.002876 0.004584 0.000164 0.001104 0.001528 0.001200
#> [105] 0.000148 0.001096 0.001388 0.002188 0.000084 0.002716 0.001720 0.000148
#> [113] 0.004716 0.003784 0.000084 0.003936 0.000204 0.002636 0.003956 0.012168
#> [121] 0.001144 0.001472 0.001108 0.001304 0.001196 0.002184 0.002096 0.001108
#> [129] 0.016220 0.003920 0.004060 0.003324 0.028744 0.003952 0.005580 0.003424
#> [137] 0.003156 0.003388 0.015112 0.023060 0.002976 0.004532 0.012904 0.019180
#> [145] 0.003112 0.004508 0.018756 0.000140 0.000768 0.003396 0.005956 0.012120
#> [153] 0.004668 0.001752 0.016572 0.004792 0.015208 0.001152 0.008104 0.003320
#> [161] 0.004512 0.043832 0.003076 0.005404 0.001288 0.001652 0.001076 0.008108
#> [169] 0.002244 0.003576 0.030056 0.012236 0.003944 0.000164 0.000976 0.003416
#> [177] 0.000980 0.001956 0.001964 0.000168 0.000140 0.001640 0.001956 0.000148
#> [185] 0.001808 0.001636 0.000568 0.001912 0.000100 0.000832 0.000904 0.002944
#> [193] 0.000224 0.002788 0.001120 0.003092 0.000584 0.002060 0.003944 0.002916
#> [201] 0.000652 0.003264 0.002940 0.004384 0.004116 0.004064 0.002796 0.004192
#> [209] 0.002668 0.003920 0.002936 0.004088 0.002768 0.001236 0.000840 0.001764
#> [217] 0.000076 0.000352 0.002592 0.000532 0.003452 0.000608 0.002268 0.001268
#> [225] 0.002700 0.002892 0.004120 0.000192 0.002544 0.003968 0.002888 0.003984
#> [233] 0.002876 0.004200 0.004024 0.000276 0.000304 0.004832 0.005004 0.004228
#> [241] 0.004272 0.000156 0.004052 0.002652 0.004060 0.000520 0.002280 0.003944
#> [249] 0.002912 0.000084 0.004092 0.002684 0.004004 0.002852 0.004036 0.002824
#> [257] 0.004392 0.000168 0.003940 0.000688 0.003492 0.002676 0.003936 0.002924
#> [265] 0.004152 0.002704 0.003840 0.000312 0.002708 0.002640 0.001368 0.002852
#> [273] 0.003956 0.002900 0.004164 0.002696 0.003968 0.000108 0.002780 0.000892
#> [281] 0.003096 0.002872 0.003448 0.000576 0.002832 0.001240 0.002696 0.000236
#> [289] 0.002688 0.001832 0.002312 0.002712 0.004308 0.002552 0.004028 0.002832
#> [297] 0.003964 0.002200 0.000692 0.004308 0.002060 0.002132 0.000888 0.003136
#> [305] 0.001380 0.001456 0.004020 0.002836 0.003976 0.002884 0.003960 0.002900
#> [313] 0.003960 0.002896 0.002912 0.001132 0.002816 0.003996 0.001664 0.001196
#> [321] 0.002340 0.000148 0.001464 0.002908 0.003924 0.002936 0.003972 0.002884
#> [329] 0.004244 0.002616 0.003980 0.008076 0.004772 0.021240 0.001952 0.001960
#> [337] 0.001952 0.001952 0.001952 0.001620 0.002560 0.001756 0.000712 0.003684
#> [345] 0.002668 0.004584 0.007092 0.003952 0.010564 0.007516 0.019044 0.003540
#> [353] 0.003044 0.003488 0.010200 0.003564 0.004072 0.003504 0.052540 0.003036
#> [361] 0.005444 0.012124 0.037332 0.020336 0.004356 0.018748 0.003760 0.007084
#> [369] 0.004576 0.014284 0.003084 0.004572 0.001260 0.000148 0.001328 0.001116
#> [377] 0.001288 0.001284 0.002244 0.002076 0.001112 0.003028 0.005656 0.025340
#> [385] 0.001140 0.001476 0.001188 0.001236 0.001264 0.002204 0.002012 0.001184
#> [393] 0.006656 0.007248 0.003992 0.004512 0.004108 0.002748 0.004016 0.000164
#> [401] 0.001244 0.001200 0.000236 0.001212 0.001156 0.001524 0.001312 0.000872
#> [409] 0.002876 0.000148 0.001184 0.003788 0.003528 0.002928 0.001020 0.000120
#> [417] 0.002788 0.004024 0.000168 0.001788 0.000880 0.001080 0.001952 0.001180
#> [425] 0.000896 0.001828 0.000148 0.002688 0.001940 0.000888 0.000888 0.000892
#> [433] 0.000168 0.000888 0.001428 0.000360 0.000948 0.001396 0.002340 0.000076
#> [441] 0.002948 0.000792 0.001376 0.001300 0.001400 0.000164 0.000996 0.001540
#> [449] 0.001132 0.001208 0.000148 0.002032 0.002796 0.000168 0.001308 0.000084
#> [457] 0.002112 0.004188 0.000172 0.002500 0.003972 0.002884 0.002368 0.001620
#> [465] 0.002868 0.003988 0.002872 0.003960 0.003632 0.000144 0.001164 0.001296
#> [473] 0.001240 0.001268 0.000168 0.001312 0.002052 0.000176 0.003188 0.001508
#> [481] 0.000164 0.002860 0.001112 0.000144 0.001056 0.001196 0.001212 0.001196
#> [489] 0.000284 0.001916 0.001940 0.000144 0.000980 0.000148 0.000080 0.003504
#> [497] 0.001704 0.000952 0.001132 0.002648 0.001644 0.001860 0.000708 0.004068
#> [505] 0.002788 0.003940 0.001256 0.001424 0.000240 0.000972 0.001404 0.002040
#> [513] 0.001764 0.000168 0.002808 0.000080 0.001132 0.000148 0.001508 0.001192
#> [521] 0.001328 0.001260 0.000168 0.001292 0.001116 0.000084 0.000552 0.000540
#> [529] 0.001204 0.001744 0.001552 0.003308 0.000212 0.003988 0.002868 0.004108
#> [537] 0.002752 0.003952 0.002904 0.004148 0.001212 0.000084 0.001212 0.000204
#> [545] 0.001592 0.001112 0.001256 0.001268 0.000168 0.002016 0.001088 0.000888
#> [553] 0.001228 0.003940 0.002444 0.003960 0.002896 0.002528 0.001716 0.002616
#> [561] 0.001488 0.002480 0.000476 0.002264 0.000152 0.003332 0.000620 0.002904
#> [569] 0.004868 0.000160 0.001068 0.001228 0.001224 0.000144 0.001064 0.001224
#> [577] 0.001428 0.000304 0.002680 0.000160 0.001056 0.003172 0.002632 0.004044
#> [585] 0.002812 0.002268 0.001768 0.002224 0.001236 0.000144 0.003956 0.002900
#> [593] 0.004052 0.002812 0.004004 0.001652 0.001200 0.001328 0.002132 0.000548
#> [601] 0.001812 0.000076 0.000964 0.003972 0.001724 0.001160 0.000980 0.002972
#> [609] 0.000172 0.001200 0.001352 0.000184 0.002036 0.001480 0.000556 0.002224
#> [617] 0.000560 0.003060 0.001416 0.000132 0.000168 0.000892 0.001428 0.001104
#> [625] 0.000172 0.000148 0.000960 0.002184 0.000916 0.001028 0.000168 0.000996
#> [633] 0.000144 0.002104 0.002320 0.002976 0.001324 0.001880 0.003972 0.002888
#> [641] 0.003976 0.004524 0.004012 0.002844 0.000988 0.001132 0.001468 0.001112
#> [649] 0.000168 0.001040 0.001488 0.001308 0.001180 0.002056 0.001124 0.004504
#> [657] 0.005872 0.001156 0.005652 0.020652 0.001220 0.001476 0.001316 0.000888
#> [665] 0.000912 0.000888 0.000904 0.000888 0.000900 0.000920 0.000888 0.000908
#> [673] 0.000888 0.000080 0.000140 0.000956 0.000924 0.001104 0.000904 0.000888
#> [681] 0.000900 0.000892 0.001116 0.001172 0.001952 0.001120 0.004940 0.004420
#> [689] 0.005244 0.002152 0.002756 0.000132 0.002144 0.001800 0.003008 0.003120
#> [697] 0.001116 0.001264 0.001360 0.000888 0.001068 0.000136 0.000892 0.000932
#> [705] 0.000380 0.001572 0.000888 0.001068 0.000132 0.001400 0.000892 0.000372
#> [713] 0.000924 0.002772 0.000432 0.001328 0.000888 0.000888 0.000892 0.000296
#> [721] 0.000892 0.001704 0.001108 0.001296 0.001252 0.000216 0.001284 0.001604
#> [729] 0.000600 0.002020 0.001204 0.000304 0.007224 0.011096 0.002204 0.002172
#> [737] 0.004148 0.004224 0.006592 0.004080 0.004132 0.004592 0.005516 0.002524
#> [745] 0.001428 0.003048 0.001820 0.002316 0.001596 0.001496 0.001564 0.002492
#> [753] 0.002924 0.000372 0.002024 0.003456 0.004376 0.002008 0.002512 0.004336
#> [761] 0.005000 0.003040 0.001152 0.002804 0.000860 0.002180 0.000928 0.002440
#> [769] 0.001152 0.004024 0.003624 0.000372 0.002156 0.003704 0.003004 0.003484
#> [777] 0.002828 0.003572 0.004444 0.004920 0.000140 0.001072 0.004016 0.003604
#> [785] 0.003876 0.003832 0.002500 0.003608 0.004088 0.006196 0.014896 0.005340
#> [793] 0.000132 0.004648 0.001136 0.003416 0.003116 0.004452 0.000088 0.002456
#> [801] 0.002252 0.006692 0.001156 0.002248 0.001324 0.001816 0.002540 0.000656
#> [809] 0.004140 0.000320 0.003344 0.000612 0.002764 0.002160 0.000224 0.004192
#> [817] 0.002836 0.003076 0.002732 0.000488 0.004060 0.000988 0.003452 0.004052
#> [825] 0.002808 0.004108 0.001308 0.001440 0.004068 0.002792 0.004212 0.002648
#> [833] 0.004120 0.002736 0.003956 0.001048 0.001856 0.002048 0.002156 0.001328
#> [841] 0.001324 0.000888 0.003200 0.000168 0.002604 0.002240 0.001544 0.000336
#> [849] 0.001800 0.000940 0.000452 0.002616 0.000452 0.002444 0.000240 0.000732
#> [857] 0.002888 0.000316 0.004088 0.000168 0.002600 0.000536 0.002716 0.000324
#> [865] 0.000596 0.002688 0.000100 0.000084 0.003372 0.000736 0.000276 0.002212
#> [873] 0.001720 0.000592 0.001692 0.002500 0.000272 0.001492 0.001952 0.001084
#> [881] 0.000404 0.003276 0.000984 0.002008 0.000168 0.000576 0.001204 0.001956
#> [889] 0.000148 0.000128 0.000692 0.000980 0.001952 0.000144 0.001808 0.000084
#> [897] 0.001560 0.001012 0.001544 0.000136 0.001628 0.000728 0.000784 0.003112
#> [905] 0.000552 0.004052 0.000388 0.003788 0.000788 0.000188 0.001708 0.003984
#> [913] 0.002872 0.004224 0.002636 0.003224 0.000824 0.002808 0.000148 0.003056
#> [921] 0.000724 0.002676 0.000256 0.004148 0.002708 0.004000 0.001388 0.001472
#> [929] 0.003476 0.003732 0.001148 0.000096 0.001148 0.001216 0.000216 0.001000
#> [937] 0.001180 0.000140 0.000412 0.000556 0.000776 0.002336 0.000144 0.001008
#> [945] 0.000096 0.001604 0.001416 0.001220 0.001516 0.003704 0.000572 0.002584
#> [953] 0.001112 0.002820 0.000160 0.002764 0.004156 0.002704 0.003916 0.002944
#> [961] 0.000784 0.003200 0.000244 0.003060 0.001208 0.002348 0.001572 0.002940
#> [969] 0.004084 0.004168 0.000248 0.003336 0.000612 0.003756 0.000796 0.004172
#> [977] 0.000100 0.000168 0.002956 0.001104 0.000160 0.001844 0.002764 0.000332
#> [985] 0.001648 0.001752 0.000876 0.001800 0.001080 0.000288 0.001088 0.000912
#> [993] 0.000812 0.001740 0.000236 0.000344 0.001860 0.002680 0.000900 0.000152
Using this point data, we can estimate parameters for general MAP with 5 states, MMPP with 5 states and ER-HMM with 5 states by the following commands, respectively;
## mapfit for general MAP
mapfit.point(map=map(5), x=cumsum(BCpAug89))
#>
#> Maximum LLF: 5122.534283
#> DF: 49
#> AIC: -10147.068566
#> Iteration: 2000 / 2000
#> Computation time (user): 72.704000
#> Convergence: FALSE
#> Error (abs): 1.498159e-04 (tolerance Inf)
#> Error (rel): 2.924644e-08 (tolerance 1.490116e-08)
#>
#> Size : 5
#> Initial : 0.1603438 0.1711041 0.3232155 0.1724821 0.1728545
#> Infinitesimal generator D0:
#> 5 x 5 Matrix of class "dgeMatrix"
#> [,1] [,2] [,3] [,4] [,5]
#> [1,] -1.720628e+03 1.220294e+03 2.220531e-09 1.801320e-12 2.420524e-23
#> [2,] 9.559413e-14 -1.459595e+03 4.716531e-26 1.408366e+03 1.845559e-15
#> [3,] 7.131167e-09 6.930977e-04 -1.214721e+02 5.892926e+00 2.000251e-05
#> [4,] 1.135388e-33 8.220767e-41 2.805414e-28 -1.479720e+03 1.458977e+03
#> [5,] 6.102793e-71 3.169232e-135 1.109230e-32 2.940132e-41 -1.455834e+03
#> Infinitesimal generator D1:
#> 5 x 5 Matrix of class "dgeMatrix"
#> [,1] [,2] [,3] [,4] [,5]
#> [1,] 1.739651e+02 3.263687e+02 2.986680e-230 3.678877e-05 3.329270e-29
#> [2,] 3.695446e-47 1.826671e-05 1.751724e-191 5.122940e+01 3.044409e-40
#> [3,] 5.788336e-83 5.393613e+00 1.101849e+02 3.444119e-86 5.585843e-187
#> [4,] 3.916670e-27 3.501582e-11 3.382059e-113 2.074297e+01 4.687940e-06
#> [5,] 1.434720e+03 7.972563e-03 2.110570e+01 1.529094e-21 5.435371e-11
## mapfit for general MMPP
mapfit.point(map=mmpp(5), x=cumsum(BCpAug89))
#>
#> Maximum LLF: 5055.112718
#> DF: 29
#> AIC: -10052.225436
#> Iteration: 35 / 2000
#> Computation time (user): 1.346000
#> Convergence: TRUE
#> Error (abs): 7.531932e-05 (tolerance Inf)
#> Error (rel): 1.489963e-08 (tolerance 1.490116e-08)
#>
#> Size : 5
#> Initial : 0.2390191 0.004807314 0.01941634 0.3883767 0.3483806
#> Infinitesimal generator D0:
#> 5 x 5 Matrix of class "dgeMatrix"
#> [,1] [,2] [,3] [,4] [,5]
#> [1,] -1.121570e+02 0.2395869 0.3756003 1.028355 3.213956
#> [2,] 6.083074e+01 -2933.4024676 1592.4176089 766.472038 147.987777
#> [3,] 2.042628e+00 231.1420458 -1306.0536603 703.883531 12.460843
#> [4,] 2.134376e+00 18.8580459 26.3579958 -401.780047 1.797643
#> [5,] 2.076509e-07 1.3621789 1.3046626 4.278800 -642.855329
#> Infinitesimal generator D1:
#> 5 x 5 Matrix of class "dgeMatrix"
#> [,1] [,2] [,3] [,4] [,5]
#> [1,] 107.2995 0.0000 0.0000 0.000 0.0000
#> [2,] 0.0000 365.6943 0.0000 0.000 0.0000
#> [3,] 0.0000 0.0000 356.5246 0.000 0.0000
#> [4,] 0.0000 0.0000 0.0000 352.632 0.0000
#> [5,] 0.0000 0.0000 0.0000 0.000 635.9097
## mapfit for ER-HMM
mapfit.point(map=erhmm(5), x=cumsum(BCpAug89))
#> shape: 1 1 1 1 1 llf=5037.68
#> shape: 1 1 1 2 llf=5113.80
#> shape: 1 1 3 llf=5121.86
#> shape: 1 2 2 llf=5107.05
#> shape: 1 4 llf=5003.21
#> Warning in emfit_erhmm_time(alpha, xi, rate, shape, P, data, options, H):
#> Warning: LLF does not increases (iter=16, llf=5024.03, diff=-1.43212e-05)
#> shape: 2 3 llf=5024.03
#> shape: 5 llf=3716.53
#>
#> Maximum LLF: 5121.860098
#> DF: 13
#> AIC: -10217.720196
#> Iteration: 85 / 2000
#> Computation time (user): 0.763000
#> Convergence: TRUE
#> Error (abs): 7.459457e-05 (tolerance Inf)
#> Error (rel): 1.456396e-08 (tolerance 1.490116e-08)
#>
#> Size : 3
#> Shape : 1 1 3
#> Initial : 0.4956725 0.08702603 0.4173015
#> Rate : 748.678 111.8892 1061.695
#> Transition probability :
#> 3 x 3 Matrix of class "dgeMatrix"
#> [,1] [,2] [,3]
#> [1,] 0.91944135 1.220395e-13 0.08055865
#> [2,] 0.03556987 9.053353e-01 0.05909483
#> [3,] 0.08826998 1.974182e-02 0.89198819
In the above example, cumsum is a function to derive cumulative sums because BCpAug89 provides time difference data. The estimation with erhmm is much faster than others.
Next we present MAP fitting with grouped data. The grouped data is made from BCpAug89 by using hist function, i.e.,
BCpAug89.group<-hist(cumsum(BCpAug89), breaks=seq(0,2.7,0.01), plot=FALSE)
BCpAug89.group$breaks
#> [1] 0.00 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 0.10 0.11 0.12 0.13 0.14
#> [16] 0.15 0.16 0.17 0.18 0.19 0.20 0.21 0.22 0.23 0.24 0.25 0.26 0.27 0.28 0.29
#> [31] 0.30 0.31 0.32 0.33 0.34 0.35 0.36 0.37 0.38 0.39 0.40 0.41 0.42 0.43 0.44
#> [46] 0.45 0.46 0.47 0.48 0.49 0.50 0.51 0.52 0.53 0.54 0.55 0.56 0.57 0.58 0.59
#> [61] 0.60 0.61 0.62 0.63 0.64 0.65 0.66 0.67 0.68 0.69 0.70 0.71 0.72 0.73 0.74
#> [76] 0.75 0.76 0.77 0.78 0.79 0.80 0.81 0.82 0.83 0.84 0.85 0.86 0.87 0.88 0.89
#> [91] 0.90 0.91 0.92 0.93 0.94 0.95 0.96 0.97 0.98 0.99 1.00 1.01 1.02 1.03 1.04
#> [106] 1.05 1.06 1.07 1.08 1.09 1.10 1.11 1.12 1.13 1.14 1.15 1.16 1.17 1.18 1.19
#> [121] 1.20 1.21 1.22 1.23 1.24 1.25 1.26 1.27 1.28 1.29 1.30 1.31 1.32 1.33 1.34
#> [136] 1.35 1.36 1.37 1.38 1.39 1.40 1.41 1.42 1.43 1.44 1.45 1.46 1.47 1.48 1.49
#> [151] 1.50 1.51 1.52 1.53 1.54 1.55 1.56 1.57 1.58 1.59 1.60 1.61 1.62 1.63 1.64
#> [166] 1.65 1.66 1.67 1.68 1.69 1.70 1.71 1.72 1.73 1.74 1.75 1.76 1.77 1.78 1.79
#> [181] 1.80 1.81 1.82 1.83 1.84 1.85 1.86 1.87 1.88 1.89 1.90 1.91 1.92 1.93 1.94
#> [196] 1.95 1.96 1.97 1.98 1.99 2.00 2.01 2.02 2.03 2.04 2.05 2.06 2.07 2.08 2.09
#> [211] 2.10 2.11 2.12 2.13 2.14 2.15 2.16 2.17 2.18 2.19 2.20 2.21 2.22 2.23 2.24
#> [226] 2.25 2.26 2.27 2.28 2.29 2.30 2.31 2.32 2.33 2.34 2.35 2.36 2.37 2.38 2.39
#> [241] 2.40 2.41 2.42 2.43 2.44 2.45 2.46 2.47 2.48 2.49 2.50 2.51 2.52 2.53 2.54
#> [256] 2.55 2.56 2.57 2.58 2.59 2.60 2.61 2.62 2.63 2.64 2.65 2.66 2.67 2.68 2.69
#> [271] 2.70
BCpAug89.group$counts
#> [1] 4 3 6 4 5 5 2 4 2 3 2 3 3 3 5 5 2 3 5 5 4 8 8 3 4
#> [26] 8 4 5 1 5 4 0 3 1 0 0 2 3 1 1 0 1 2 0 1 1 2 0 4 1
#> [51] 1 2 0 2 0 2 3 0 0 0 0 2 4 3 0 0 1 0 5 9 8 5 4 2 3
#> [76] 3 4 8 4 4 3 4 2 3 4 4 3 3 4 4 2 5 3 4 4 6 4 3 4 4
#> [101] 4 3 3 4 6 3 2 3 2 0 0 5 5 3 2 0 2 0 1 3 1 3 0 0 0
#> [126] 0 0 3 0 1 0 0 1 0 1 1 0 2 2 0 3 7 4 0 0 4 5 1 3 2
#> [151] 10 4 5 8 9 7 10 6 4 4 3 8 6 10 7 5 6 8 11 4 4 2 10 5 3
#> [176] 6 5 8 6 4 5 3 6 6 8 8 11 5 3 2 9 4 2 1 0 8 13 6 2 5
#> [201] 5 12 10 9 3 1 4 1 3 2 5 5 3 4 3 6 4 3 3 4 2 3 2 0 3
#> [226] 3 5 3 4 7 3 4 3 4 3 3 6 5 9 5 8 7 8 11 9 4 5 3 6 4
#> [251] 4 12 8 5 4 3 6 2 6 7 8 8 2 0 0 0 0 0 0 0
In the above, break points are set as a time point sequence from 0 to 2.7 by 0.01, which is generated by a seq function. Using the grouped data, we have the estimated parameters for general MAP, MMPP and MMPP with approximate estimation (gmmpp).
## mapfit for general MAP with grouped data
mapfit.group(map=map(5), counts=BCpAug89.group$counts, breaks=BCpAug89.group$breaks)
#>
#> Maximum LLF: -554.776073
#> DF: 49
#> AIC: 1207.552145
#> Iteration: 2000 / 2000
#> Computation time (user): 127.523000
#> Convergence: FALSE
#> Error (abs): 2.654024e-04 (tolerance Inf)
#> Error (rel): 4.783953e-07 (tolerance 1.490116e-08)
#>
#> Size : 5
#> Initial : 0.06328003 0.3507495 0.2356264 0.07035194 0.2799922
#> Infinitesimal generator D0:
#> 5 x 5 Matrix of class "dgeMatrix"
#> [,1] [,2] [,3] [,4] [,5]
#> [1,] -1.841592e+03 1.553891e-15 1.157789e+02 5.084803e-03 3.051464e-12
#> [2,] 1.003815e-10 -9.809545e+01 5.777257e-04 8.248668e-12 4.940656e-324
#> [3,] 4.395244e-01 8.862347e-05 -4.846395e+02 8.671099e+00 4.267835e-75
#> [4,] 1.596055e+03 1.750864e-13 1.563358e+01 -1.674587e+03 4.769906e-09
#> [5,] 1.391710e-63 1.906085e-05 5.963354e-15 7.803157e-64 -3.612557e+02
#> Infinitesimal generator D1:
#> 5 x 5 Matrix of class "dgeMatrix"
#> [,1] [,2] [,3] [,4] [,5]
#> [1,] 3.399102e+01 2.879076e-09 8.778286e-01 1.672897e+03 1.804263e+01
#> [2,] 5.167392e+00 9.139872e+01 1.528764e+00 4.216854e-07 4.940656e-324
#> [3,] 7.758472e-01 8.364457e+00 4.429568e+02 2.343168e+01 2.903017e-110
#> [4,] 9.517915e-03 1.575820e-32 5.215542e-05 6.232805e+01 5.608927e-01
#> [5,] 3.846468e-81 1.349904e+00 2.868759e+00 1.050595e-74 3.570370e+02
## mapfit for general MMPP with grouped data
mapfit.group(map=mmpp(5), counts=BCpAug89.group$counts, breaks=BCpAug89.group$breaks)
#>
#> Maximum LLF: -556.527050
#> DF: 29
#> AIC: 1171.054100
#> Iteration: 687 / 2000
#> Computation time (user): 72.267000
#> Convergence: TRUE
#> Error (abs): 8.230252e-06 (tolerance Inf)
#> Error (rel): 1.478859e-08 (tolerance 1.490116e-08)
#>
#> Size : 5
#> Initial : 0.3371581 0.1733851 0.002042279 0.2116746 0.2757399
#> Infinitesimal generator D0:
#> 5 x 5 Matrix of class "dgeMatrix"
#> [,1] [,2] [,3] [,4] [,5]
#> [1,] -9.812065e+01 4.855140e+00 9.548377e-02 2.125667 2.192511e-117
#> [2,] 4.489278e-10 -8.587724e+02 2.533694e+01 40.377084 6.772455e+00
#> [3,] 6.409872e-05 1.816304e+03 -4.030291e+03 1745.481400 2.260435e-06
#> [4,] 9.615866e+00 3.411710e+01 1.345895e+01 -504.782486 1.676778e-21
#> [5,] 1.270740e+00 1.555820e-17 6.729164e-11 2.987776 -3.624054e+02
#> Infinitesimal generator D1:
#> 5 x 5 Matrix of class "dgeMatrix"
#> [,1] [,2] [,3] [,4] [,5]
#> [1,] 91.04435 0.0000 0.0000 0.0000 0.0000
#> [2,] 0.00000 786.2859 0.0000 0.0000 0.0000
#> [3,] 0.00000 0.0000 468.5052 0.0000 0.0000
#> [4,] 0.00000 0.0000 0.0000 447.5906 0.0000
#> [5,] 0.00000 0.0000 0.0000 0.0000 358.1468
## mapfit for general MMPP with grouped data (approximation)
mapfit.group(map=gmmpp(5), counts=BCpAug89.group$counts, breaks=BCpAug89.group$breaks)
#>
#> Maximum LLF: -828.214536
#> DF: 29
#> AIC: 1714.429073
#> Iteration: 137 / 2000
#> Computation time (user): 5.562000
#> Convergence: TRUE
#> Error (abs): 1.174183e-05 (tolerance Inf)
#> Error (rel): 1.417728e-08 (tolerance 1.490116e-08)
#>
#> Size : 5
#> Initial : 0.2516258 0.183785 0.1965876 0.1946077 0.1733939
#> Infinitesimal generator D0:
#> 5 x 5 Matrix of class "dgeMatrix"
#> [,1] [,2] [,3] [,4] [,5]
#> [1,] -1.086551e+03 3.290412e-18 4.976078e-12 96.21832293 1.034133e-10
#> [2,] 1.098316e-18 -9.465068e+01 9.457765e+01 0.07125943 1.769756e-03
#> [3,] 4.619582e+00 8.816451e+01 -2.981280e+02 9.05755345 6.497892e-07
#> [4,] 1.960721e+01 1.478413e-13 1.297276e-12 -569.58623102 8.040788e+01
#> [5,] 8.750462e-11 9.490825e-10 9.122291e+00 90.01656338 -4.662285e+02
#> Infinitesimal generator D1:
#> 5 x 5 Matrix of class "dgeMatrix"
#> [,1] [,2] [,3] [,4] [,5]
#> [1,] 990.3329 0.000000e+00 0.0000 0.0000 0.0000
#> [2,] 0.0000 3.801572e-11 0.0000 0.0000 0.0000
#> [3,] 0.0000 0.000000e+00 196.2863 0.0000 0.0000
#> [4,] 0.0000 0.000000e+00 0.0000 469.5711 0.0000
#> [5,] 0.0000 0.000000e+00 0.0000 0.0000 367.0896
References
- [1] G. Horvath, P. Buchholz and M. Telek, A MAP fitting approach with independent approximation of the inter-arrival time distribution and the lag correlation, Proceedings of the 2nd International Conference on the Quantitative Evaluation of Systems (QEST2005), 124-133, 2005.
- [2] H. Okamura and T. Dohi, Faster maximum likelihood estimation algorithms for Markovian arrival processes, Proceedings of 6th International Conference on Quantitative Evaluation of Systems (QEST2009), 73-82, 2009.
- [3] H. Okamura, T. Dohi and K.S. Trivedi, Markovian arrival process parameter estimation with group data, IEEE/ACM Transactions on Networking, 17(4), 1326-1339, 2009.