Extensible Framework for Data Pattern Exploration.
![]()
![]()
![]()
nuggets
nuggets is a package for R statistical computing environment providing a framework for systematic exploration of association rules (Agrawal (1994)), contrast patterns (Chen (2022)), emerging patterns (Dong (1999)), subgroup discovery (Atzmueller (2015)), and conditional correlations (Hájek (1978)). User-defined functions may also be supplied to guide custom pattern searches.
Supports both crisp (Boolean) and fuzzy data. Generates candidate conditions expressed as elementary conjunctions, evaluates them on a dataset, and inspects the induced sub-data for statistical, logical, or structural properties such as associations, correlations, or contrasts. Includes methods for visualization of logical structures and supports interactive exploration through integrated Shiny applications.
What Patterns Can You Discover?
- Association Rules: “University educated people in middle age working in IT have high income” – identify conditions that strongly predict specific outcomes
- Conditional Correlations: “Study time correlates with test score on hard exams” – discover relationships between variables that only hold under certain conditions
- Complement Contrasts: “Smokers have lower life expectancy than non-smokers” – find subgroups with significantly different characteristics from the rest
- Baseline Contrasts: “Measurement error differs from zero when using tool A” – detect when a variable deviates significantly from a baseline under specific conditions
- Paired Contrasts: “Ice cream sales exceed tea sales on sunny days” – compare paired measurements within specific contexts
- Custom Patterns: Define your own evaluation functions for specialized pattern mining
Key Features
- Optimized performance for fast computation.
- Support for both categorical and numeric data.
- Provides both Boolean and fuzzy logic approach.
- Data preparation functions for easy pre-processing phase.
- Functions for examining associations, conditional correlations, and contrasts among data variables.
- Visualization and pattern post-processing tools.
- Integrated Shiny applications for interactive exploration of discovered patterns.
Fast on Dense Datasets
A lot of effort has been put into optimizing the performance of the package, especially for dense datasets. The core algorithms are implemented in C++ and use single-instruction multiple-data (SIMD) operations to speed up the operations.
On a randomly generated dataset with 1 million rows and 15 columns, association rules with at most 5 items in the antecedent, a support above 0.001, and a confidence above 0.5 were searched. The total times, including reading the data from the CSV file, searching for rules, and writing the result back to CSV, on a Linux desktop computer with standard installations of the packages, were as follows:
nuggets(R, boolean logic): 1.4 sarules- ECLAT (R, boolean logic): 2.9 sarules- Apriori (R, boolean logic): 3.3 s
Fuzzy variant of association rules, which is much more computationally intensive:
nuggets(R, fuzzy logic): 12.0 s
For comparison, two Python libraries performed as follows:
cleverminer(Python, boolean logic): 1m 15.0smlxtend(Python, boolean logic, frequent itemsets only): 4h 11m 22.5s
Documentation
Read the full documentation of the nuggets package.
Installation
To install the stable version of nuggets from CRAN, type the following command within the R session:
install.packages("nuggets")
You can also install the development version of nuggets from GitHub with:
install.packages("devtools")
devtools::install_github("beerda/nuggets")
To start using the package, load it to the R session with:
library(nuggets)
Minimal Example
The following example demonstrates how to use nuggets to find association rules in the built-in mtcars dataset:
# Preprocess: dichotomize and fuzzify numeric variables
cars <- mtcars |>
partition(cyl, vs:gear, .method = "dummy") |>
partition(carb, .method = "crisp", .breaks = c(0, 3, 10)) |>
partition(mpg, disp:qsec, .method = "triangle", .breaks = 3)
# Search for associations among conditions
rules <- dig_associations(cars,
antecedent = everything(),
consequent = everything(),
max_length = 4,
min_support = 0.1)
# Add various interest measures
rules <- add_interest(rules)
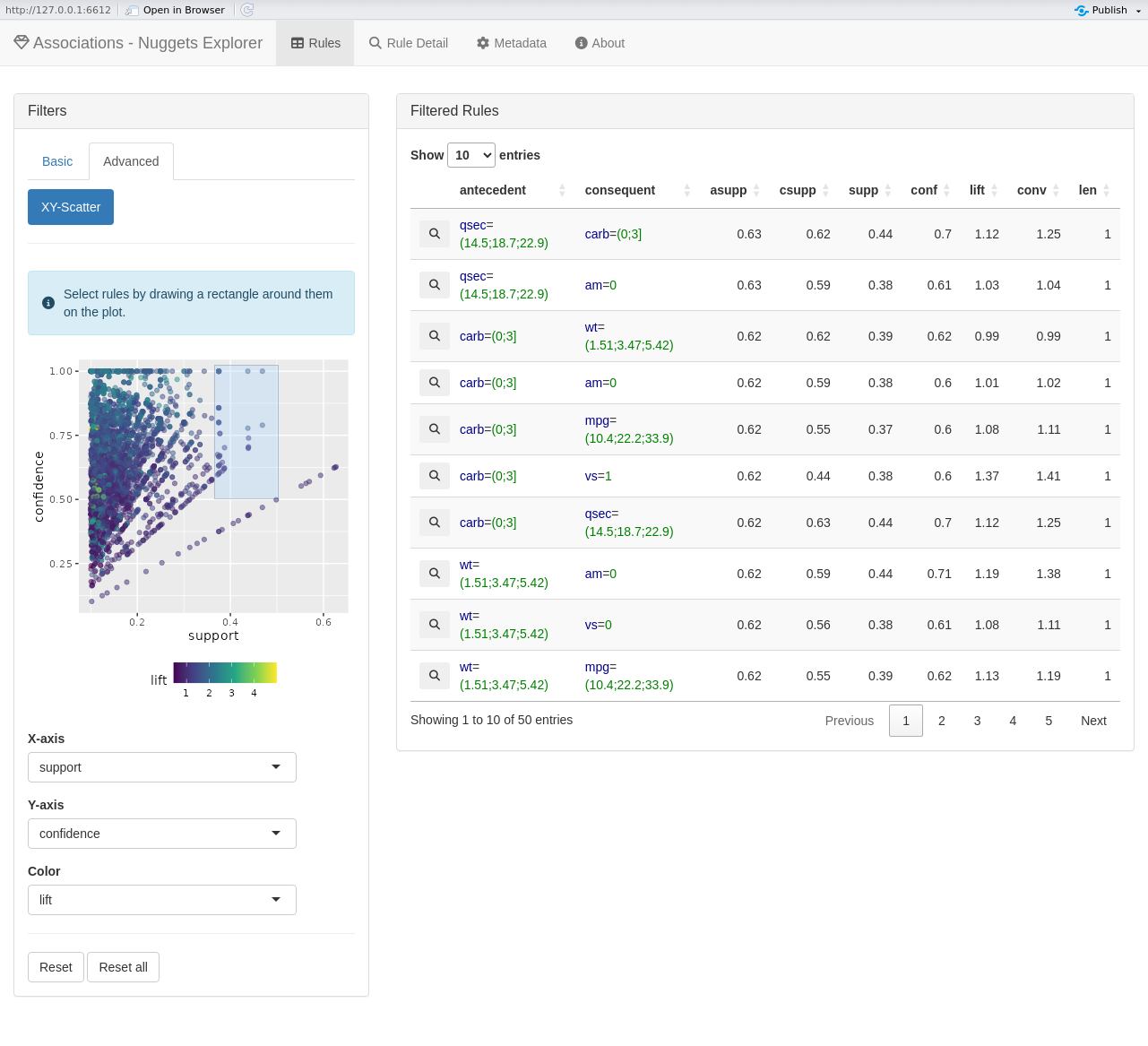
# Explore the found rules interactively
explore(rules, cars)
Contributing
Contributions, suggestions, and bug reports are welcome. Please submit issues on GitHub.
License
This package is licensed under the GPL-3 license.
It includes third-party code licensed under BSD-2-Clause, BSD-3-Clause, and GPL-2 or later licenses. See inst/COPYRIGHTS for details.