Latent Dirichlet Allocation Using 'tidyverse' Conventions.
tidylda 

![]()
![]()
![]()
Latent Dirichlet Allocation Using ‘tidyverse’ Conventions
tidylda implements an algorithm for Latent Dirichlet Allocation using style conventions from the tidyverse and tidymodels.
In addition this implementation of LDA allows you to:
- use asymmetric prior parameters alpha and eta
- use a matrix prior parameter, eta, to seed topics into a model
- use a previously-trained model as a prior for a new model
- apply LDA in a transfer-learning paradigm, updating a model’s parameters with additional data (or additional iterations)
Installation
You can install the latest CRAN release with:
install("tidylda")
You can install the development version from GitHub with:
install.packages("remotes")
remotes::install_GitHub("tommyjones/tidylda")
For a list of dependencies see the DESCRIPTION file.
Getting started
This package is still in its early stages of development. However, some basic functionality is below. Here, we will use the tidytext package to create a document term matrix, fit a topic model, predict topics of unseen documents, and update the model with those new documents.
tidylda uses the following naming conventions for topic models:
thetais a matrix whose rows are distributions of topics over documents, or P(topic|document)betais a matrix whose rows are distributions of tokens over topics, or P(token|topic)lambdais a matrix whose rows are distributions of topics over tokens, or P(topic|token)lambdais useful for making predictions with a computationally-simple and efficient dot product and it may be interesting to analyze in its own right.alphais the prior that tunesthetaetais the prior that tunesbeta
Example
library(tidytext)
library(dplyr)
#>
#> Attaching package: 'dplyr'
#> The following objects are masked from 'package:stats':
#>
#> filter, lag
#> The following objects are masked from 'package:base':
#>
#> intersect, setdiff, setequal, union
library(ggplot2)
library(tidyr)
library(tidylda)
#> tidylda is under active development. The API and behavior may change.
library(Matrix)
#>
#> Attaching package: 'Matrix'
#> The following objects are masked from 'package:tidyr':
#>
#> expand, pack, unpack
### Initial set up ---
# load some documents
docs <- nih_sample
# tokenize using tidytext's unnest_tokens
tidy_docs <- docs %>%
select(APPLICATION_ID, ABSTRACT_TEXT) %>%
unnest_tokens(output = word,
input = ABSTRACT_TEXT,
stopwords = stop_words$word,
token = "ngrams",
n_min = 1, n = 2) %>%
count(APPLICATION_ID, word) %>%
filter(n>1) #Filtering for words/bigrams per document, rather than per corpus
tidy_docs <- tidy_docs %>% # filter words that are just numbers
filter(! stringr::str_detect(tidy_docs$word, "^[0-9]+$"))
# append observation level data
colnames(tidy_docs)[1:2] <- c("document", "term")
# turn a tidy tbl into a sparse dgCMatrix
# note tidylda has support for several document term matrix formats
d <- tidy_docs %>%
cast_sparse(document, term, n)
# let's split the documents into two groups to demonstrate predictions and updates
d1 <- d[1:50, ]
d2 <- d[51:nrow(d), ]
# make sure we have different vocabulary for each data set to simulate the "real world"
# where you get new tokens coming in over time
d1 <- d1[, colSums(d1) > 0]
d2 <- d2[, colSums(d2) > 0]
### fit an intial model and inspect it ----
set.seed(123)
lda <- tidylda(
data = d1,
k = 10,
iterations = 200,
burnin = 175,
alpha = 0.1, # also accepts vector inputs
eta = 0.05, # also accepts vector or matrix inputs
optimize_alpha = FALSE, # experimental
calc_likelihood = TRUE,
calc_r2 = TRUE, # see https://arxiv.org/abs/1911.11061
return_data = FALSE
)
# did the model converge?
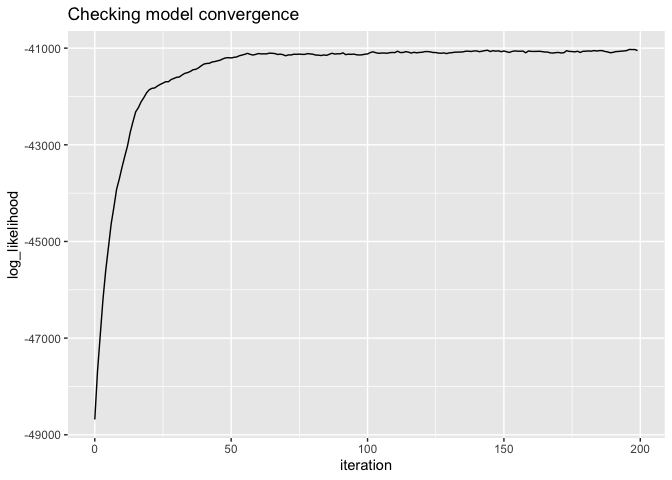
# there are actual test stats for this, but should look like "yes"
qplot(x = iteration, y = log_likelihood, data = lda$log_likelihood, geom = "line") +
ggtitle("Checking model convergence")
#> Warning: `qplot()` was deprecated in ggplot2 3.4.0.
#> This warning is displayed once every 8 hours.
#> Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
#> generated.
# look at the model overall
glance(lda)
#> # A tibble: 1 × 5
#> num_topics num_documents num_tokens iterations burnin
#> <int> <int> <int> <dbl> <dbl>
#> 1 10 50 1524 200 175
print(lda)
#> A Latent Dirichlet Allocation Model of 10 topics, 50 documents, and 1524 tokens:
#> tidylda(data = d1, k = 10, iterations = 200, burnin = 175, alpha = 0.1,
#> eta = 0.05, optimize_alpha = FALSE, calc_likelihood = TRUE,
#> calc_r2 = TRUE, return_data = FALSE)
#>
#> The model's R-squared is 0.2503
#> The 5 most prevalent topics are:
#> # A tibble: 10 × 4
#> topic prevalence coherence top_terms
#> <dbl> <dbl> <dbl> <chr>
#> 1 4 12.5 0.0527 cdk5, cns, develop, based, lsds, ...
#> 2 3 11.5 0.170 cells, cell, sleep, specific, memory, ...
#> 3 1 11.4 0.114 effects, v4, signaling, stiffening, wall, ...
#> 4 6 10.9 0.348 diabetes, numeracy, redox, extinction, health, ...
#> 5 8 10.7 0.337 cmybp, function, mitochondrial, injury, fragment, …
#> # ℹ 5 more rows
#>
#> The 5 most coherent topics are:
#> # A tibble: 10 × 4
#> topic prevalence coherence top_terms
#> <dbl> <dbl> <dbl> <chr>
#> 1 6 10.9 0.348 diabetes, numeracy, redox, extinction, health, ...
#> 2 8 10.7 0.337 cmybp, function, mitochondrial, injury, fragment, …
#> 3 7 10.3 0.210 cancer, imaging, cells, rb, tumor, ...
#> 4 5 9.13 0.206 program, dcis, cancer, research, disparities, ...
#> 5 10 8.53 0.19 sud, plasticity, risk, factors, brain, ...
#> # ℹ 5 more rows
# it comes with its own summary matrix that's printed out with print(), above
lda$summary
#> # A tibble: 10 × 4
#> topic prevalence coherence top_terms
#> <dbl> <dbl> <dbl> <chr>
#> 1 1 11.4 0.114 effects, v4, signaling, stiffening, wall, ...
#> 2 2 7.01 0.0779 research, natural, antibodies, hiv, core, ...
#> 3 3 11.5 0.170 cells, cell, sleep, specific, memory, ...
#> 4 4 12.5 0.0527 cdk5, cns, develop, based, lsds, ...
#> 5 5 9.13 0.206 program, dcis, cancer, research, disparities, ...
#> 6 6 10.9 0.348 diabetes, numeracy, redox, extinction, health, ...
#> 7 7 10.3 0.210 cancer, imaging, cells, rb, tumor, ...
#> 8 8 10.7 0.337 cmybp, function, mitochondrial, injury, fragment,…
#> 9 9 8 0.184 ppg, core, pd, data, imaging, ...
#> 10 10 8.53 0.19 sud, plasticity, risk, factors, brain, ...
# inspect the individual matrices
tidy_theta <- tidy(lda, matrix = "theta")
tidy_theta
#> # A tibble: 500 × 3
#> document topic theta
#> <chr> <dbl> <dbl>
#> 1 8574224 1 0.00238
#> 2 8574224 2 0.00524
#> 3 8574224 3 0.00238
#> 4 8574224 4 0.00429
#> 5 8574224 5 0.00238
#> 6 8574224 6 0.00238
#> 7 8574224 7 0.00238
#> 8 8574224 8 0.00238
#> 9 8574224 9 0.00238
#> 10 8574224 10 0.974
#> # ℹ 490 more rows
tidy_beta <- tidy(lda, matrix = "beta")
tidy_beta
#> # A tibble: 15,240 × 3
#> topic token beta
#> <dbl> <chr> <dbl>
#> 1 1 adolescence 0.0025
#> 2 1 age 0.0000648
#> 3 1 application 0.0000648
#> 4 1 depressive 0.0000648
#> 5 1 disorder 0.0000648
#> 6 1 emotionality 0.0000648
#> 7 1 information 0.0025
#> 8 1 mdd 0.0000648
#> 9 1 onset 0.0000648
#> 10 1 onset mdd 0.0000648
#> # ℹ 15,230 more rows
tidy_lambda <- tidy(lda, matrix = "lambda")
tidy_lambda
#> # A tibble: 15,240 × 3
#> topic token lambda
#> <dbl> <chr> <dbl>
#> 1 1 adolescence 0.304
#> 2 1 age 0.00938
#> 3 1 application 0.00794
#> 4 1 depressive 0.0206
#> 5 1 disorder 0.0206
#> 6 1 emotionality 0.0206
#> 7 1 information 0.259
#> 8 1 mdd 0.0115
#> 9 1 onset 0.00795
#> 10 1 onset mdd 0.0206
#> # ℹ 15,230 more rows
# append observation-level data
augmented_docs <- augment(lda, data = tidy_docs)
#> Joining with `by = join_by(document, term, n)`
augmented_docs
#> # A tibble: 4,566 × 4
#> document term n topic
#> <chr> <chr> <int> <int>
#> 1 8574224 adolescence 1 10
#> 2 8646901 adolescence 1 10
#> 3 8689019 adolescence 1 10
#> 4 8705323 adolescence 1 10
#> 5 8574224 age 1 10
#> 6 8705323 age 1 10
#> 7 8757072 age 1 10
#> 8 8823186 age 1 10
#> 9 8574224 application 1 10
#> 10 8605875 application 1 10
#> # ℹ 4,556 more rows
### predictions on held out data ---
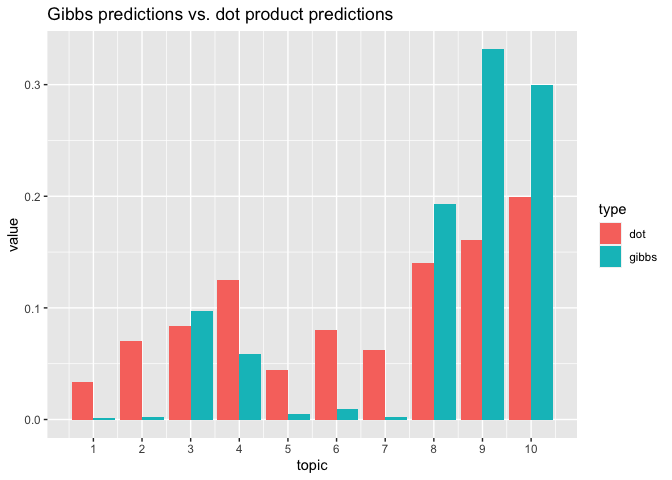
# two methods: gibbs is cleaner and more technically correct in the bayesian sense
p_gibbs <- predict(lda, new_data = d2[1, ], iterations = 100, burnin = 75)
# dot is faster, less prone to error (e.g. underflow), noisier, and frequentist
p_dot <- predict(lda, new_data = d2[1, ], method = "dot")
# pull both together into a plot to compare
tibble(topic = 1:ncol(p_gibbs), gibbs = p_gibbs[1,], dot = p_dot[1, ]) %>%
pivot_longer(cols = gibbs:dot, names_to = "type") %>%
ggplot() +
geom_bar(mapping = aes(x = topic, y = value, group = type, fill = type),
stat = "identity", position="dodge") +
scale_x_continuous(breaks = 1:10, labels = 1:10) +
ggtitle("Gibbs predictions vs. dot product predictions")
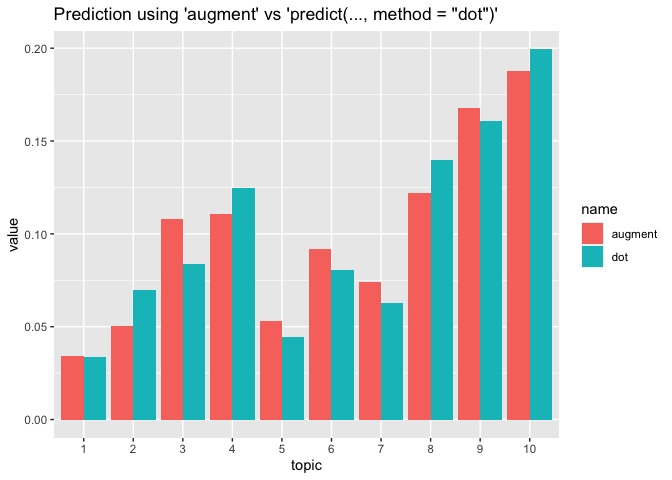
### Augment as an implicit prediction using the 'dot' method ----
# Aggregating over terms results in a distribution of topics over documents
# roughly equivalent to using the "dot" method of predictions.
augment_predict <-
augment(lda, tidy_docs, "prob") %>%
group_by(document) %>%
select(-c(document, term)) %>%
summarise_all(function(x) sum(x, na.rm = T))
#> Joining with `by = join_by(document, term, n)`
#> Adding missing grouping variables: `document`
# reformat for easy plotting
augment_predict <-
as_tibble(t(augment_predict[, -c(1,2)]), .name_repair = "minimal")
colnames(augment_predict) <- unique(tidy_docs$document)
augment_predict$topic <- 1:nrow(augment_predict) %>% as.factor()
compare_mat <-
augment_predict %>%
select(
topic,
augment = matches(rownames(d2)[1])
) %>%
mutate(
augment = augment / sum(augment), # normalize to sum to 1
dot = p_dot[1, ]
) %>%
pivot_longer(cols = c(augment, dot))
ggplot(compare_mat) +
geom_bar(aes(y = value, x = topic, group = name, fill = name),
stat = "identity", position = "dodge") +
labs(title = "Prediction using 'augment' vs 'predict(..., method = \"dot\")'")
# Not shown: aggregating over documents results in recovering the "tidy" lambda.
### updating the model ----
# now that you have new documents, maybe you want to fold them into the model?
lda2 <- refit(
object = lda,
new_data = d, # save me the trouble of manually-combining these by just using d
iterations = 200,
burnin = 175,
calc_likelihood = TRUE,
calc_r2 = TRUE
)
# we can do similar analyses
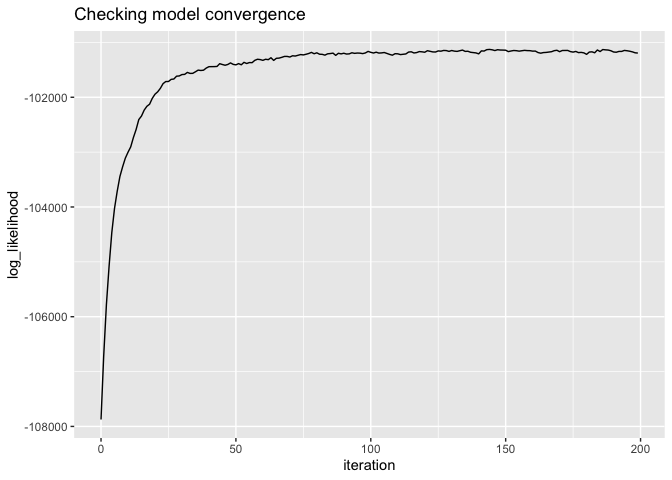
# did the model converge?
qplot(x = iteration, y = log_likelihood, data = lda2$log_likelihood, geom = "line") +
ggtitle("Checking model convergence")
# look at the model overall
glance(lda2)
#> # A tibble: 1 × 5
#> num_topics num_documents num_tokens iterations burnin
#> <int> <int> <int> <dbl> <dbl>
#> 1 10 99 2962 200 175
print(lda2)
#> A Latent Dirichlet Allocation Model of 10 topics, 99 documents, and 2962 tokens:
#> refit.tidylda(object = lda, new_data = d, iterations = 200, burnin = 175,
#> calc_likelihood = TRUE, calc_r2 = TRUE)
#>
#> The model's R-squared is 0.1389
#> The 5 most prevalent topics are:
#> # A tibble: 10 × 4
#> topic prevalence coherence top_terms
#> <dbl> <dbl> <dbl> <chr>
#> 1 5 14.5 0.107 research, program, cancer, health, disparities, ...
#> 2 3 12.6 0.141 cell, cells, lung, sleep, specific, ...
#> 3 1 11.9 0.0616 effects, muscle, wall, v4, signaling, ...
#> 4 10 10.4 0.0499 risk, brain, factors, sud, plasticity, ...
#> 5 2 10.2 0.0305 research, center, microbiome, core, hiv, ...
#> # ℹ 5 more rows
#>
#> The 5 most coherent topics are:
#> # A tibble: 10 × 4
#> topic prevalence coherence top_terms
#> <dbl> <dbl> <dbl> <chr>
#> 1 8 7.34 0.326 cmybp, function, mitochondrial, injury, fragment, …
#> 2 9 7.55 0.187 core, data, ppg, studies, imaging, ...
#> 3 7 9.9 0.159 cancer, tumor, clinical, imaging, cells, ...
#> 4 3 12.6 0.141 cell, cells, lung, sleep, specific, ...
#> 5 5 14.5 0.107 research, program, cancer, health, disparities, ...
#> # ℹ 5 more rows
# how does that compare to the old model?
print(lda)
#> A Latent Dirichlet Allocation Model of 10 topics, 50 documents, and 1524 tokens:
#> tidylda(data = d1, k = 10, iterations = 200, burnin = 175, alpha = 0.1,
#> eta = 0.05, optimize_alpha = FALSE, calc_likelihood = TRUE,
#> calc_r2 = TRUE, return_data = FALSE)
#>
#> The model's R-squared is 0.2503
#> The 5 most prevalent topics are:
#> # A tibble: 10 × 4
#> topic prevalence coherence top_terms
#> <dbl> <dbl> <dbl> <chr>
#> 1 4 12.5 0.0527 cdk5, cns, develop, based, lsds, ...
#> 2 3 11.5 0.170 cells, cell, sleep, specific, memory, ...
#> 3 1 11.4 0.114 effects, v4, signaling, stiffening, wall, ...
#> 4 6 10.9 0.348 diabetes, numeracy, redox, extinction, health, ...
#> 5 8 10.7 0.337 cmybp, function, mitochondrial, injury, fragment, …
#> # ℹ 5 more rows
#>
#> The 5 most coherent topics are:
#> # A tibble: 10 × 4
#> topic prevalence coherence top_terms
#> <dbl> <dbl> <dbl> <chr>
#> 1 6 10.9 0.348 diabetes, numeracy, redox, extinction, health, ...
#> 2 8 10.7 0.337 cmybp, function, mitochondrial, injury, fragment, …
#> 3 7 10.3 0.210 cancer, imaging, cells, rb, tumor, ...
#> 4 5 9.13 0.206 program, dcis, cancer, research, disparities, ...
#> 5 10 8.53 0.19 sud, plasticity, risk, factors, brain, ...
#> # ℹ 5 more rows
There are several vignettes available in /vignettes. They can be compiled using knitr or you can view PDF versions on CRAN.
See NEWS.md for a changelog, including changes from the CRAN release to the development version on GitHub.
See the “Issues” tab on GitHub to see planned features as well as bug fixes.
Contributions
If you would like to contribute to this package, please start by opening an issue on GitHub. Direct contributions via merge requests are discouraged unless invited to do so.
If you have any suggestions for additional functionality, changes to functionality, changes to arguments or other aspects of the API please let me know by opening an issue on GitHub or sending me an email: jones.thos.w at gmail.com.
Code of Conduct
Please note that the tidylda project is released with a Contributor Code of Conduct. By contributing to this project, you agree to abide by its terms.